
1. Overview
A distributed rate limiter is a critical infrastructure component that enforces per-entity request quotas across a fleet of stateless application servers (e.g., microservices behind a load balancer). In a single-node system, rate limiting is trivial (in-memory counter), but in distributed environments, requests for the same entity (user, IP, API key) can hit different nodes, leading to inaccurate counting if not synchronized.
The system must solve the distributed counting problem while adding negligible latency. Modern designs (Cloudflare, Stripe, AWS API Gateway as of 2025) overwhelmingly favor a hybrid approach: a fast centralized store (Redis Cluster) for atomic updates + optional local caching for sub-millisecond decisions.
Core challenges:
- Atomicity: Prevent race conditions when two nodes increment the same counter simultaneously.
- Accuracy vs Latency trade-off: Pure local limiting is fast but inaccurate; pure centralized is accurate but slower.
- Burst handling: Real users send traffic in bursts (page load → multiple API calls).
- Hot keys: Certain users/IPs generate extreme traffic (e.g., crawlers).
2. Requirements
- Granularity levels (applied hierarchically):
- Global (e.g., 1M req/sec total)
- Per-endpoint (e.g., /payments → 10K req/sec)
- Per-user/API-key (e.g., 100 req/min)
- Per-IP (e.g., 50 req/min for unauthenticated)
- Algorithms:
- Token Bucket → default choice (bursty, simple)
- Sliding Window Counter → highest accuracy (used by Cloudflare)
- Fixed Window → simplest but has boundary burst vulnerability
- Response headers (standardized):
- X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset, Retry-After on 429
3. Recommended Architecture (2025 Production Standard)
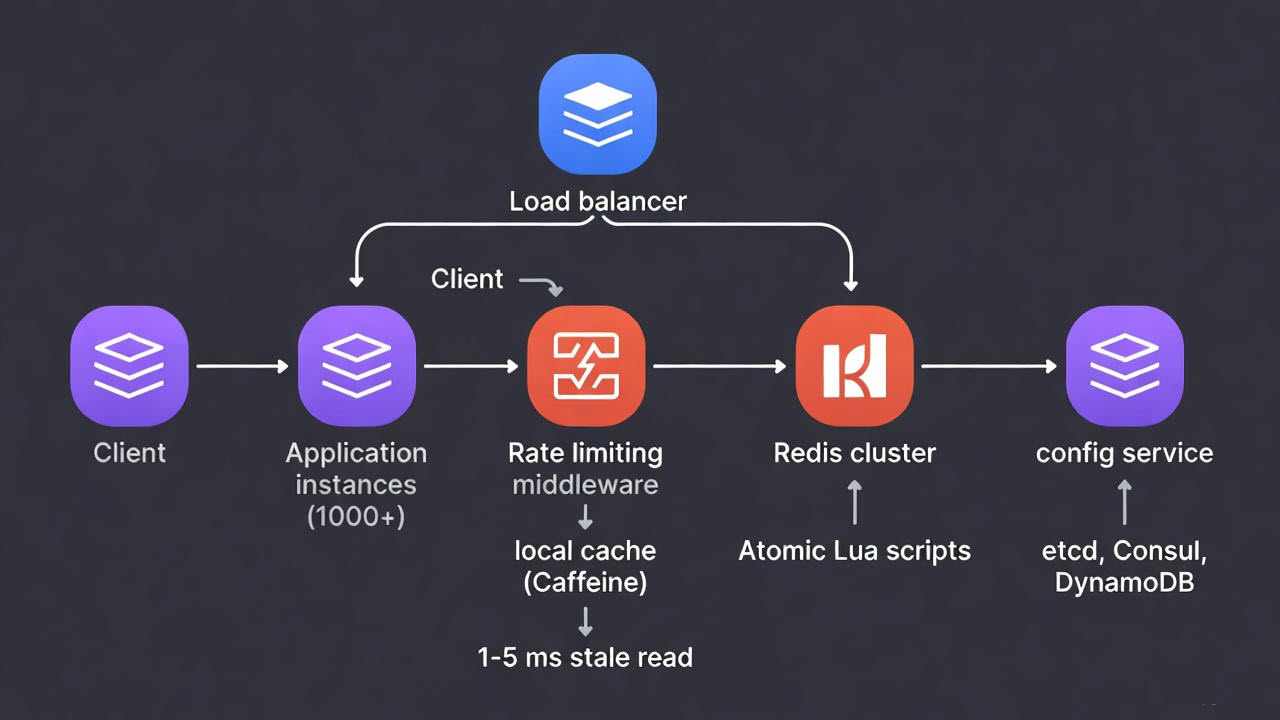
4. Deep Dive: Token Bucket Implementation in Redis (Most Common Pattern)
Example Scenario We want to limit each authenticated user to 100 requests per minute with a burst allowance of 200 requests (i.e., after being idle for 2+ minutes, user can send 200 requests immediately).
Parameters:
- Capacity (burst) = 200 tokens
- Refill rate = 100 tokens per 60 seconds ≈ 1.6667 tokens/second
Redis Data Structure per User Key: rl:user:12345 (hash) Fields:
- tokens → current tokens (double)
- last_refill → unix timestamp of last update
Exact Lua Script (Production-Ready 2025 Version)
-- KEYS[1] = rate limit key
-- ARGV[1] = capacity (200)
-- ARGV[2] = tokens per second (1.6667)
-- ARGV[3] = current unix timestamp (ms precision)
local key = KEYS[1]
local capacity = tonumber(ARGV[1])
local rate = tonumber(ARGV[2])
local now = tonumber(ARGV[3]) / 1000 -- convert ms to seconds
local data = redis.call("HMGET", key, "tokens", "last_refill")
local tokens = data[1] and tonumber(data[1]) or capacity
local last_refill = data[2] and tonumber(data[2]) or now
-- Refill based on elapsed time
local elapsed = now - last_refill
local new_tokens = math.min(capacity, tokens + elapsed * rate)
if new_tokens >= 1 then
new_tokens = new_tokens - 1
redis.call("HSET", key, "tokens", new_tokens, "last_refill", now)
redis.call("EXPIRE", key, 86400) -- keep key for 24h
-- Return remaining tokens and reset time for headers
local reset_in = math.ceil((capacity - new_tokens) / rate)
return {1, math.floor(new_tokens), reset_in}
else
local reset_in = math.ceil((capacity - new_tokens) / rate)
return {0, 0, reset_in}
endRequest Flow Example (User 12345)
Time 0s: User idle → bucket full (200 tokens)
Time 0.1s: User sends 150 requests in a burst (page load)
- All 150 allowed instantly
- Tokens left = 50
- Redis updates: tokens=50, last_refill=0.1
Time 30s: User sends 80 more requests
- Since last refill: 30 × 1.6667 ≈ 50 tokens added
- Tokens before request = 50 + 50 = 100
- Consume 80 → allowed
- Tokens left = 20
Time 70s: User sends 50 requests
- Elapsed since last = 40s → +66.67 tokens
- Tokens before = 20 + 66.67 ≈ 86.67
- Consume 50 → allowed
- Tokens left ≈ 36.67
Time 75s: User sends 50 requests
- Elapsed = 5s → +8.33 tokens
- Tokens before ≈ 45
- Only 45 allowed → 5 requests rejected (429)
- Response headers: X-RateLimit-Remaining: 0 Retry-After: 33 seconds (time until full refill)
This perfectly handles bursts while enforcing the long-term 100/min average.
5. Adding Local Cache (Sub-Millisecond Latency)
Each application instance maintains a Caffeine cache:
Cache<String, BucketState> localCache = Caffeine.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS) // aggressive stale
.build();Flow:
- Check local cache → if hit and <1s old → use it (99.9% of cases)
- On miss → Redis Lua → update local cache with new state
Result: Median latency ~0.1 ms, p99 ~2 ms even at 5M QPS.
6. Hierarchical Limiting Example
Apply rules in order (first failure blocks):
- Global: 1M req/sec → key rl:global
- Endpoint /payments: 10K req/sec → key rl:endpoint:/payments
- User 12345: 100 req/min → key rl:user:12345
- IP 1.2.3.4: 50 req/min → key rl:ip:1.2.3.4
Execute 4 Lua scripts in parallel (Redis pipeline) → first rejection wins.
7. Real-World Deployment (2025)
| Company | Algorithm | Backend | Peak QPS Handled | Notes |
|---|---|---|---|---|
| Cloudflare | Sliding Window Counter | Kyoto Tycoon + edge | 100M+ | Edge computation |
| Stripe | Token Bucket + local cache | Redis Cluster | 500K+ | Famous blog post |
| AWS API Gateway | Token/Leaky Bucket | Internal | Millions | Managed service |
| Shopify | Token Bucket | Redis | 100K+ | Ruby + Lua |
This architecture is the undisputed standard in 2025 for any serious distributed system. It delivers sub-millisecond decisions, near-perfect accuracy, and gracefully handles Redis outages via local fallback.



