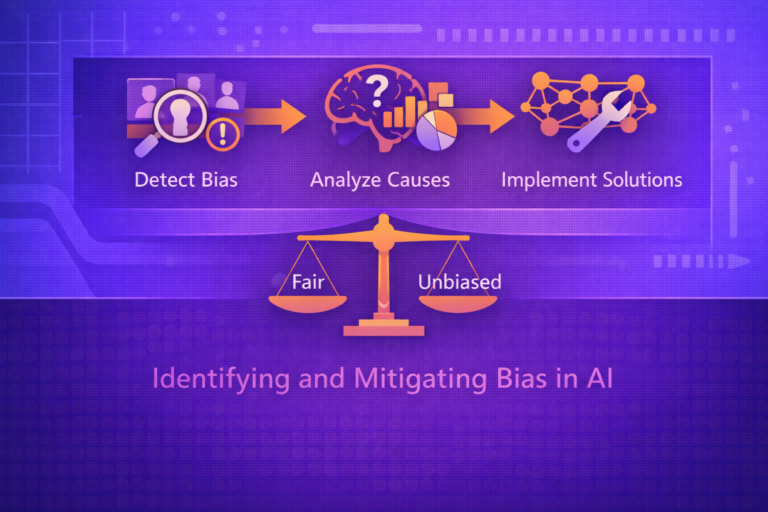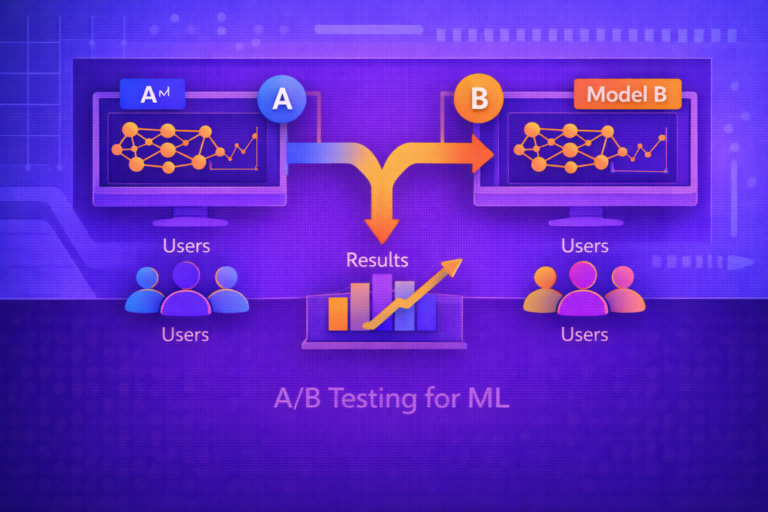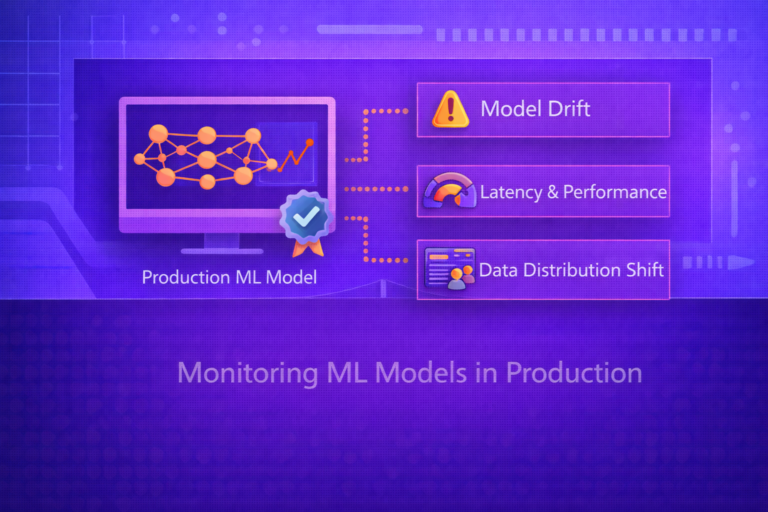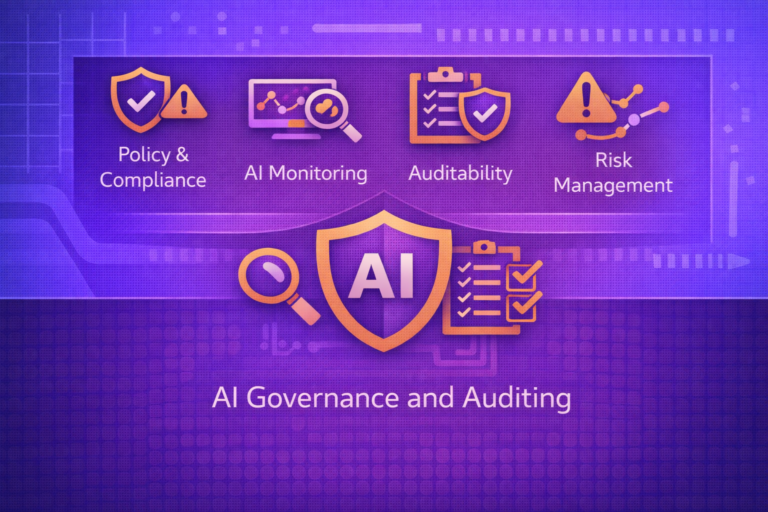
AI Governance and Auditing
AI governance and auditing are the organizational and technical disciplines used to ensure that AI systems are designed, deployed, and operated within defined legal, ethical, operational, and business boundaries. Governance establishes policies, accountability, controls, and decision rights. Auditing evaluates whether…