
1. Overview
This case study presents a comprehensive design for a fully distributed, highly available, and linearly scalable key-value store, directly modeled after Amazon’s Dynamo technology (the foundational system behind DynamoDB, Riak, Cassandra, and Voldemort).
The core philosophy is radical decentralization: no single point of failure, no master node, and no special roles. Every node is identical and can act as a coordinator for any request. The system deliberately sacrifices strict consistency in favor of availability and partition tolerance (AP in the CAP theorem), providing eventual consistency by default while allowing clients to tune consistency strength per operation via quorum parameters (R, W, N).
This design has proven itself at extreme scale: Amazon uses it for shopping carts, session stores, product catalogs, and virtually every high-availability service requiring sub-10ms latency at millions of requests per second.
2. Functional Requirements
- Core API:
- Put(key, value, context?) → success/version
- Get(key) → value(s)/version(s)
- Value size: Up to 1 MB (sufficient for most use cases; larger objects go to S3/Blob).
- Tunable consistency: Clients specify R (reads), W (writes), N (replication factor) per request or per table.
- Common configurations:
- W=1, R=2, N=3 → high write availability, low latency
- W=2, R=2, N=3 → balanced
- W=N, R=N → strong consistency (at cost of availability)
- Common configurations:
- Conflict detection and resolution: System detects concurrent writes using vector clocks and returns all conflicting versions on read (client resolves) or applies last-writer-wins timestamp fallback.
- Conditional writes: Put succeeds only if version matches (via context from previous Get).
- No complex queries: Pure key-value (no secondary indexes in core design; add as separate layer if needed).
3. Non-Functional Requirements
- Latency: p99 ≤ 10 ms for 99% of requests under normal conditions (quorum R/W = 2).
- Throughput: 100K+ ops/sec per modern node; cluster-wide 10M+ QPS.
- Availability: 99.999% (“five 9s”) — survive multiple node failures and entire data center outages.
- Durability: Zero data loss with N=3 and proper acknowledgment.
- Scalability: Add/remove nodes with <1% data movement (thanks to virtual nodes); automatic load rebalancing.
- Partition tolerance: System remains operational during arbitrary network partitions.
- Operational simplicity: Zero-downtime scaling, rolling upgrades, automatic failure handling.
4. Capacity Estimation (Back-of-the-Envelope)
- Target workload: 10 million QPS peak, 5:1 read:write ratio.
- Per node: 10K–20K QPS (SSD-bound), → ~500–1000 nodes for 10M QPS.
- Storage: 1 billion active keys × 1 KB avg value × N=3 replication → ~3 TB raw + overhead → ~5–6 TB.
- With 10 TB SSD per node → ~600 nodes sufficient (with headroom).
- Network: 10M QPS × 1 KB payload → ~10 GB/s ingress cluster-wide → easily handled with 10 Gbps+ NICs and data center fabrics.
5. High-Level Architecture
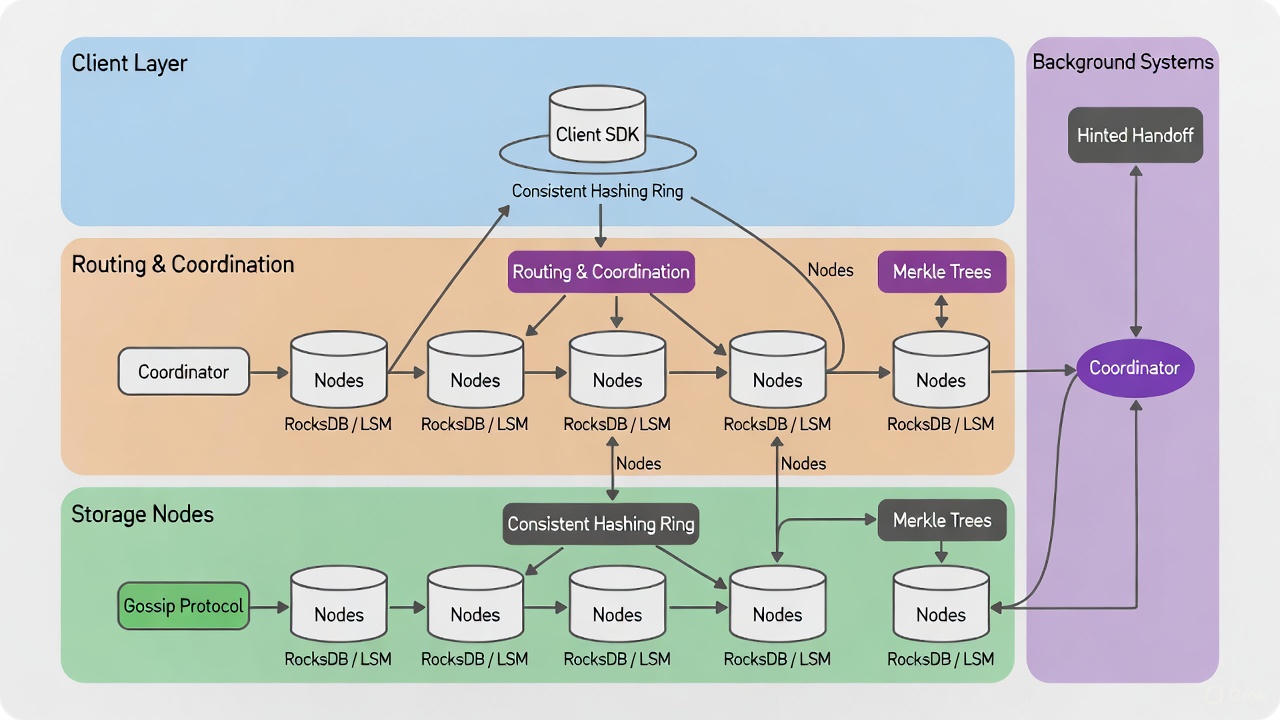
6. Core Design Decisions (Deep Dive)
6.1 Partitioning – Consistent Hashing with Virtual Nodes
- Keys hashed with MD5/SHA-256 → 256-bit space.
- Each physical node owns 100–400 virtual nodes (vnodes) evenly distributed around the ring.
- Benefits:
- Load balancing: heterogeneity handled naturally.
- Minimal data movement on node add/remove (only 1/#vnodes fraction moves).
- Smooth scaling: adding a node takes ~1/#vnodes of load from each existing node.
6.2 Replication – Sloppy Quorum + Hinted Handoff
- Preference list = next N healthy nodes clockwise from key’s position.
- Coordinator writes to first W nodes in preference list.
- If a node is down → coordinator writes to the next healthy node and records a “hint” (hinted handoff).
- When failed node recovers, hints are replayed.
- This ensures writes never fail due to node unavailability.
6.3 Consistency & Conflict Resolution – Vector Clocks
Example:
- Client A writes v1 → Node1 creates vector clock [(Node1,1)]
- Client B reads v1, writes v2 → [(Node1,1), (Node2,1)]
- Client C reads v1, writes v3 → [(Node1,1), (Node3,1)]
- Next read returns both v2 and v3 (incomparable clocks) → client merges and writes v4 [(Node1,1), (Node2,1), (Node3,1)]
This preserves causal history without requiring global coordination.
6.4 Storage Engine – Log-Structured Merge Tree (RocksDB, LevelDB, Cassandra SSTables)
- Writes → Memtable (in-memory skip list) + WAL (durability).
- Memtable flush → immutable SSTable on disk.
- Background compaction merges SSTables → excellent write amplification characteristics.
- Bloom filters on SSTables → fast negative lookups.
6.5 Failure Detection – Gossip Protocol + Φ Accrual Detector
- Every 1 second, each node gossips with 2–3 random nodes: “I am alive” + full membership view + heartbeat counters.
- Φ accrual detector outputs suspicion level (not binary alive/dead) → adaptive to network conditions.
- Seed nodes (configurable) help bootstrap new nodes.
6.6 Anti-Entropy & Repair
- Each node maintains Merkle tree for each key range it owns.
- Background process: nodes exchange Merkle root hashes → if mismatch, traverse tree to find differing keys → sync.
- Read repair: on every Get, if versions differ across replicas, coordinator writes latest version to lagging nodes.
7. Detailed Operation Flow
Put(key, value, context):
- Client → any node (coordinator via consistent hash or load balancer).
- Coordinator generates new vector clock entry for itself.
- Sends Put to top N nodes in preference list (with W quorum).
- Waits for W acknowledgments (with correct version).
- Returns success + new version to client.
Get(key):
- Coordinator sends Get to top R nodes.
- Collects versions + vector clocks.
- If multiple conflicting versions → return all (client resolves).
- Performs read repair in background.
- Returns resolved value(s).
8. Scaling, Trade-offs, and Operational Characteristics
| Aspect | Technique Used | Advantage | Trade-off / Cost |
|---|---|---|---|
| Partitioning | Consistent hashing + vnodes | Excellent load balance, minimal movement | Slightly higher ring metadata |
| Availability | Sloppy quorum + hinted handoff | Writes never fail | Temporary inconsistency during failures |
| Consistency | Vector clocks + client resolution | Causal consistency without coordination | Client complexity in conflict resolution |
| Durability | WAL + replication | Survives crashes | Write amplification |
| Repair | Merkle trees + read repair | Fast, incremental reconciliation | Background bandwidth/CPU usage |
| Strong consistency | R + W > N | Available when needed | Higher latency, lower availability |
9. Real-World Performance (DynamoDB 2025 numbers)
- Trillions of requests per day
- Peak >100M QPS
- p99 latency ~5–15 ms globally
- Automatic scaling from 1 to 100K+ capacity units without downtime
This architecture remains the gold standard for any system requiring extreme availability and operational simplicity at global scale. Modern implementations (DynamoDB, Cassandra 4+, ScyllaDB) have added features like secondary indexes, materialized views, and change data capture, but the core Dynamo principles remain unchanged and battle-tested for nearly two decades.



