Distributed Data Processing Frameworks for Large-Scale ML
Abstract
Modern machine learning systems often require processing massive datasets that exceed the capabilities of traditional data processing tools. As organizations generate vast amounts of structured, semi-structured, and unstructured data from digital platforms, sensors, and online interactions, scalable infrastructure becomes essential. Big data frameworks such as Hadoop and Apache Spark enable distributed data storage and parallel computation across clusters of machines. These technologies play a crucial role in large-scale machine learning by enabling efficient data preprocessing, feature engineering, model training, and real-time analytics. This article introduces Hadoop and Spark, explains their architectures, and discusses how they support scalable machine learning workflows.
Introduction
The rapid growth of digital technologies has led to an explosion of data across industries. Organizations collect enormous volumes of information from sources such as:
- social media platforms
- IoT devices and sensors
- financial transactions
- e-commerce platforms
- healthcare systems
- web logs and clickstream data
Traditional data processing systems struggle to handle such massive datasets due to limitations in storage capacity, processing power, and scalability.
To address these challenges, distributed computing frameworks were developed to process large datasets across clusters of machines. Among the most widely used big data technologies are Hadoop and Apache Spark.
These frameworks allow organizations to store and process data efficiently at scale, making them essential tools for building large-scale machine learning systems.
The Concept of Big Data
Big data refers to datasets that are too large or complex for traditional data processing systems.
Big data is often described using the five Vs:
Volume
Large quantities of data generated continuously.
Velocity
The speed at which data is generated and processed.
Variety
Different types of data including structured, semi-structured, and unstructured data.
Veracity
The reliability and quality of the data.
Value
The insights that can be derived from the data.
Handling big data requires distributed systems that can process information across multiple machines simultaneously.
Distributed Computing in Machine Learning
Distributed computing divides computational tasks across multiple machines in a cluster.
Instead of processing data on a single server, distributed systems split the workload into smaller pieces that are processed in parallel.
This approach provides several benefits:
- improved processing speed
- scalability for large datasets
- fault tolerance
- efficient resource utilization
Machine learning pipelines frequently rely on distributed frameworks to process large datasets before training models.
Hadoop
Overview
Hadoop is one of the earliest and most influential big data frameworks. It was developed to store and process large datasets across clusters of commodity hardware.
Hadoop is designed to handle extremely large datasets by distributing data and computation across multiple nodes.
The framework is based on two primary components:
- Hadoop Distributed File System (HDFS)
- MapReduce processing model
Together, these components enable large-scale data storage and processing.
Hadoop Distributed File System (HDFS)
HDFS is a distributed storage system designed to store massive datasets across multiple machines.
Instead of storing data on a single server, HDFS divides files into blocks and distributes them across nodes in a cluster.
Key characteristics of HDFS include:
Data replication
Each block of data is replicated across multiple nodes to ensure reliability.
Fault tolerance
If a node fails, the system automatically retrieves data from another node.
Scalability
Additional nodes can be added to increase storage capacity.
HDFS enables organizations to store petabytes of data in a distributed environment.
MapReduce Processing Model
MapReduce is Hadoop’s original computation framework for processing large datasets.
The MapReduce model operates in two main stages.
Map Stage
Data is divided into smaller chunks and processed in parallel across multiple nodes.
Reduce Stage
Intermediate results from the map stage are aggregated to produce the final output.
For example, in a word-count application:
The map stage counts word occurrences in individual text segments.
The reduce stage combines counts from all segments to produce the total frequency of each word.
Although MapReduce is powerful for batch processing, it can be relatively slow for iterative machine learning tasks.
Limitations of Hadoop for Machine Learning
While Hadoop provides excellent distributed storage and batch processing capabilities, it has several limitations for machine learning workloads.
Machine learning algorithms often require iterative processing, where data must be accessed multiple times during training.
MapReduce writes intermediate results to disk after each processing step, which introduces significant latency.
This limitation led to the development of more efficient frameworks such as Apache Spark.
Apache Spark
Overview
Apache Spark is a distributed computing framework designed to overcome many of Hadoop’s limitations.
Spark provides faster data processing by using in-memory computation, which significantly reduces disk input/output operations.
Spark supports multiple workloads, including:
- batch processing
- real-time data streaming
- machine learning
- graph analytics
Because of its flexibility and performance, Spark has become one of the most widely used platforms for big data analytics and machine learning.
Spark Architecture
Spark operates using a distributed architecture consisting of several key components.
Driver Program
The driver coordinates the execution of tasks across the cluster.
Cluster Manager
This component manages resources across multiple nodes.
Worker Nodes
Worker nodes execute computational tasks assigned by the driver.
Resilient Distributed Datasets (RDDs)
RDDs are Spark’s core data structure that enable distributed data processing.
RDDs allow data to be stored in memory across multiple machines, enabling faster processing compared to disk-based systems.
Key Features of Spark
In-memory computation
Spark processes data in memory rather than repeatedly reading from disk.
Parallel processing
Tasks are distributed across multiple nodes for faster execution.
Fault tolerance
RDDs automatically recover lost data through lineage tracking.
Flexible APIs
Spark supports programming languages such as Python, Java, Scala, and R.
These features make Spark highly suitable for machine learning workloads.
Spark and Machine Learning
Spark includes a built-in machine learning library called MLlib.
MLlib provides scalable implementations of many common machine learning algorithms.
Examples include:
- classification algorithms
- regression models
- clustering techniques
- collaborative filtering for recommendation systems
- dimensionality reduction methods
MLlib allows data scientists to train models directly on distributed datasets.
This eliminates the need to move large datasets into separate machine learning environments.
Spark for ML Pipelines
Spark supports end-to-end machine learning pipelines that include:
Data ingestion
Data is loaded from distributed storage systems such as HDFS or cloud storage.
Data preprocessing
Large datasets are cleaned and transformed using distributed operations.
Feature engineering
Features are generated across large datasets in parallel.
Model training
ML algorithms are trained on distributed data.
Model evaluation
Performance metrics are computed across large datasets.
Spark pipelines make it easier to manage complex ML workflows.
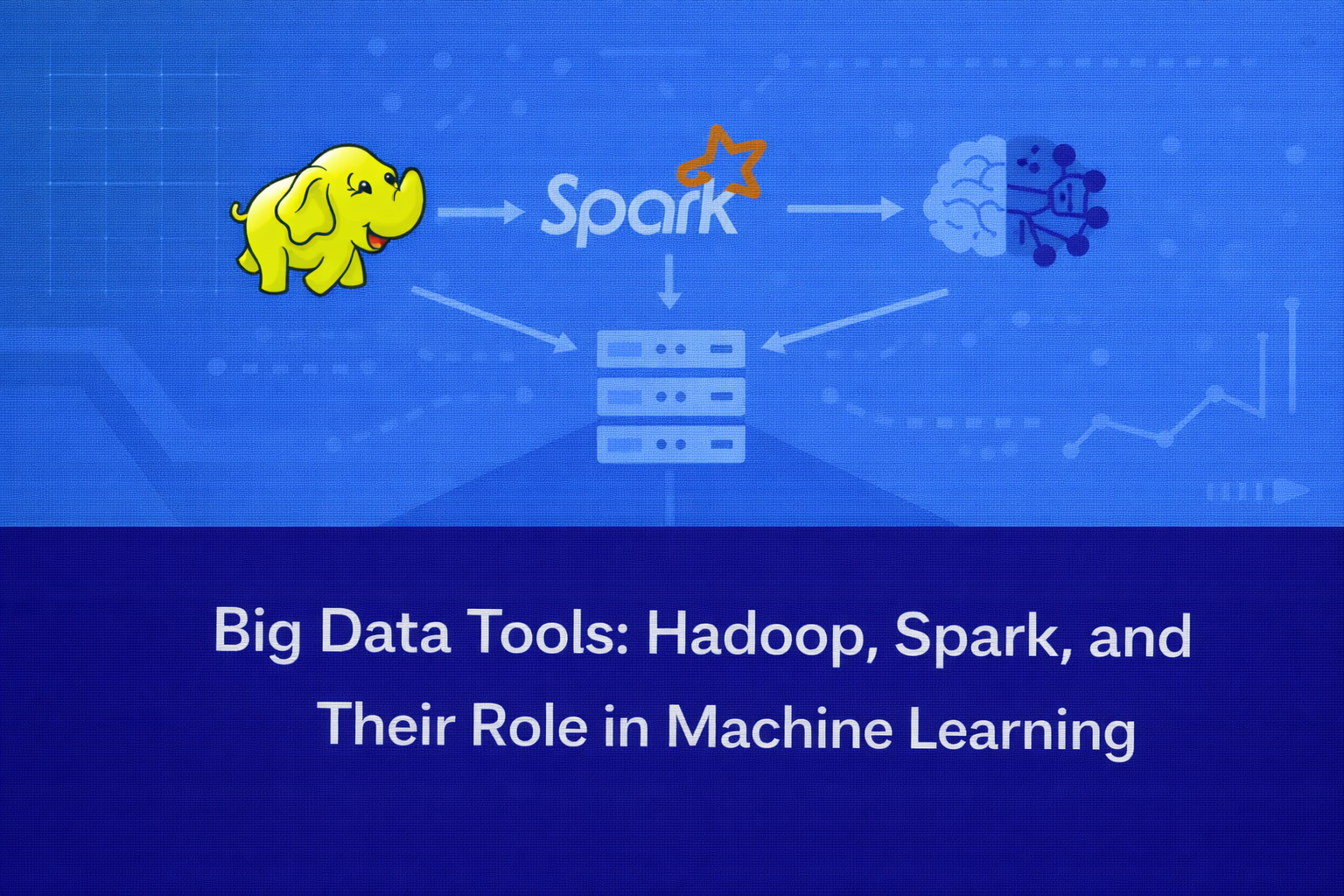
Hadoop and Spark Together
In many big data environments, Hadoop and Spark are used together.
Hadoop provides distributed storage through HDFS, while Spark performs fast data processing and machine learning tasks.
In this architecture:
HDFS stores large datasets.
Spark reads data from HDFS and processes it in memory.
This combination enables organizations to build scalable data platforms capable of supporting large-scale analytics and machine learning.
Real-World Applications
Big data frameworks support machine learning applications across many industries.
E-commerce
Online retailers analyze massive clickstream datasets to build recommendation systems and predict customer behavior.
Finance
Financial institutions analyze transaction data to detect fraud and assess risk.
Healthcare
Healthcare organizations process medical records and imaging data to improve diagnostics and treatment predictions.
Social Media
Social platforms analyze user interactions to personalize content and detect harmful behavior.
These applications require distributed systems capable of processing enormous datasets efficiently.
Challenges in Big Data ML Systems
Despite their advantages, big data frameworks introduce several challenges.
System complexity
Managing distributed clusters requires specialized expertise.
Resource management
Efficiently allocating memory and computing resources can be difficult.
Data governance
Maintaining data quality and compliance becomes more complex at scale.
Despite these challenges, distributed frameworks remain essential for large-scale machine learning.
Conclusion
As data volumes continue to grow, traditional data processing systems are no longer sufficient for modern machine learning workloads. Distributed computing frameworks such as Hadoop and Apache Spark enable organizations to store and process massive datasets efficiently.
Hadoop provides reliable distributed storage and batch processing capabilities, while Spark offers fast in-memory computation and scalable machine learning libraries. Together, these technologies form the foundation of many large-scale analytics platforms.
By leveraging distributed processing frameworks, organizations can build machine learning systems capable of analyzing vast amounts of data, uncovering insights, and delivering intelligent applications at scale.