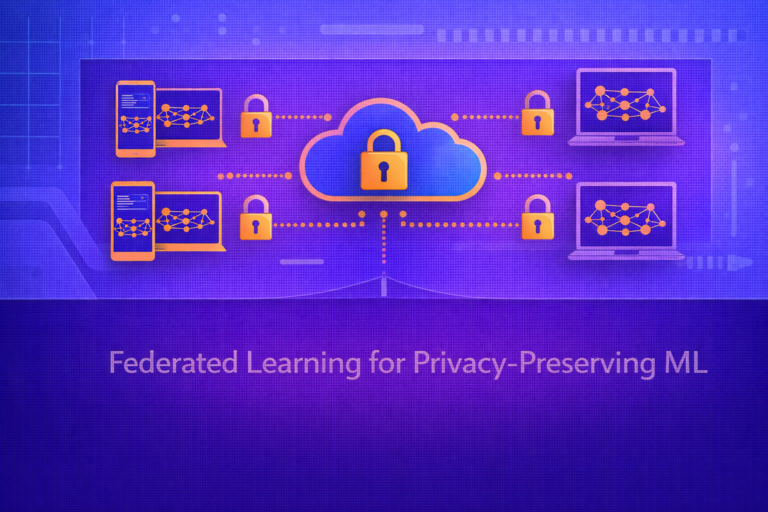
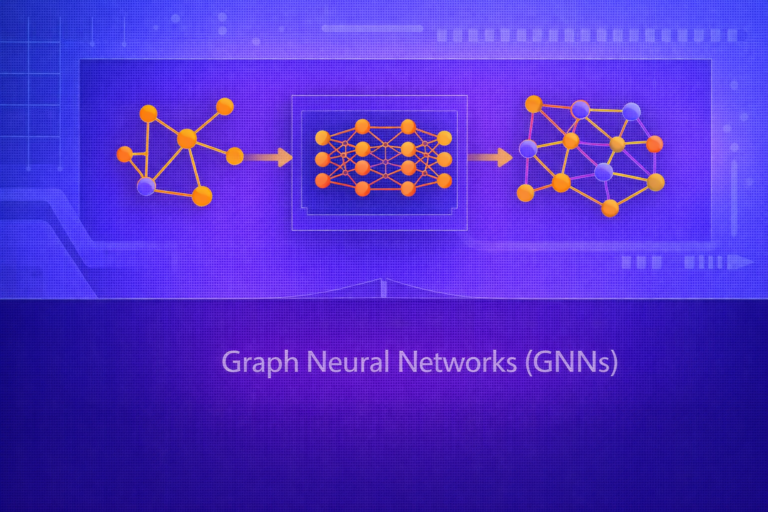
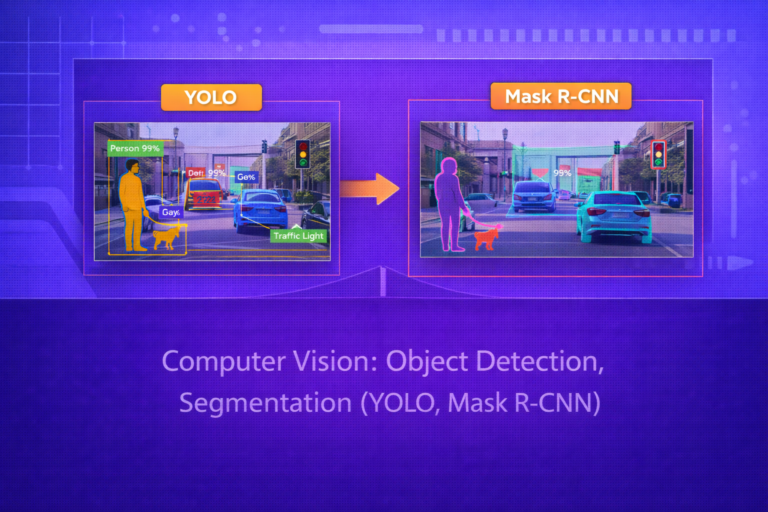
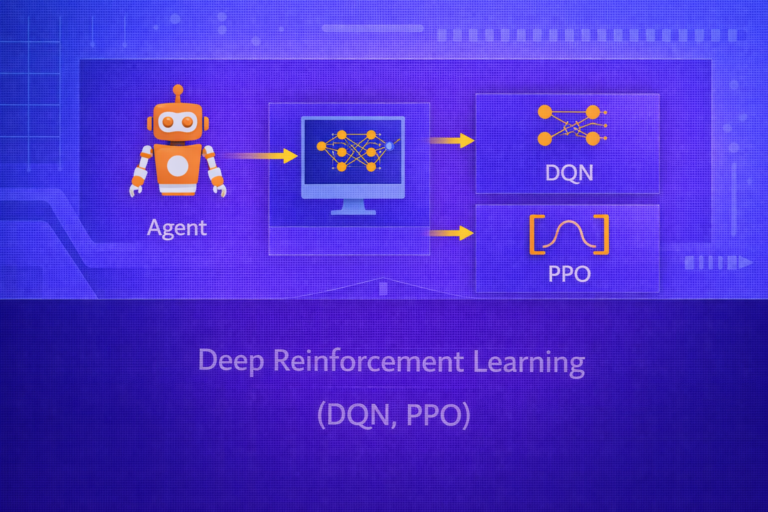
Multimodal Learning
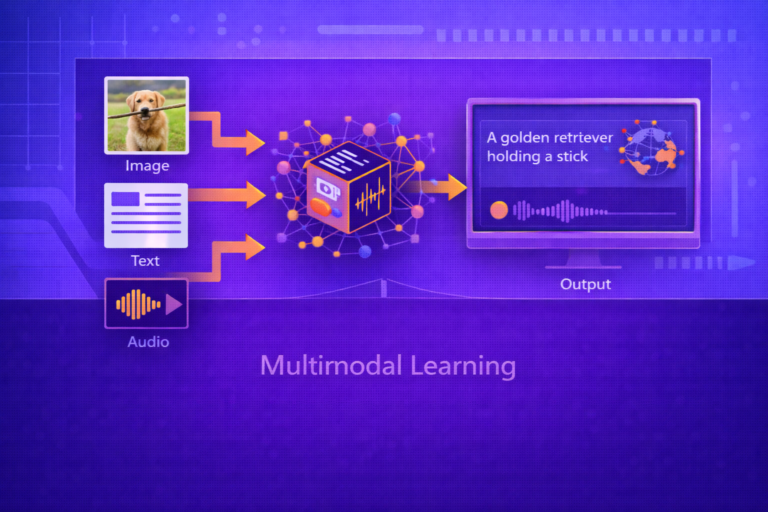
Multimodal Learning is the area of machine learning concerned with building models that can process, align, fuse, reason over, and generate information across multiple data modalities such as text, images, audio, video, graphs, sensor streams, and structured metadata. This whitepaper…