
In this case study, we examine the design of a scalable system for managing and counting “likes” on a social media platform. Such a system must handle high volumes of user interactions efficiently, ensuring reliability, low latency, and scalability to accommodate millions of users. Below, I provide a detailed explanation, covering requirements, high-level architecture, key components, data management strategies, scalability considerations, and potential challenges.
Overview
A scalable notification service constitutes an essential backend element in contemporary applications, tasked with disseminating timely and customized messages to users via diverse channels, including push notifications, email, SMS, in-app alerts, and WhatsApp. This infrastructure facilitates user engagement across platforms such as Facebook, Instagram, Uber, Slack, Amazon, and banking applications.
The architecture must accommodate substantial fan-out scenarios, wherein a single event may necessitate delivery to millions of recipients, while ensuring real-time transmission when necessary, adhering to user preferences and Do-Not-Disturb configurations, and upholding exactly-once or at-least-once delivery guarantees with elevated reliability. Notable real-world implementations encompass:
- AWS SNS integrated with SQS and Pinpoint
- Firebase Cloud Messaging (FCM)
- OneSignal or Braze
- Facebook’s Iris/Taurus systems
- Twitter’s Fanout service
The principal difficulty arises from the inverted traffic paradigm: ingress operations remain minimal (a single event), whereas egress operations escalate dramatically (dissemination to N users).
Functional Requirements
- Notification types:
- Real-time (e.g., chat messages, ride updates)
- Batch/digest (daily summaries)
- Transactional (order confirmation)
- Marketing/promotional
- Channels:
- Mobile push (APNs, FCM)
- Email (SMTP/SES)
- SMS (Twilio/Nexmo)
- In-app inbox
- Web push (VAPID)
- WebSocket for live apps
- Features:
- Templating (Handlebars/liquid) with personalization
- Localization (i18n)
- User preferences (opt-in/out per channel/topic)
- Do-Not-Disturb schedules
- Priority levels (critical vs normal)
- Tracking: delivery, open, click rates
- Rate limiting per user/channel (avoid spamming)
Non-Functional Requirements
- Scale: 1B+ users, 100M+ notifications/hour peak (e.g., Black Friday sales).
- Latency:
- Real-time: p99 < 500ms end-to-end
- Non-critical: < 10s acceptable
- Reliability: 99.999% delivery success, no lost notifications.
- Availability: Survive data center outages.
- Cost efficiency: Pay-per-delivery model in mind.
Capacity Estimation
- Peak: 100M notifications/hour → ~28K notifications/sec
- Fan-out ratio: average 1:1M recipients for marketing blasts → peak 28 billion deliveries/sec theoretically, but batched
- Storage: 1B users × 100 bytes preferences → 100 GB
- Event storage: 1 year retention → ~1 PB compressed
- Queue throughput: Kafka at 100K–1M msg/sec easily sufficient
High-Level Architecture
The architecture employs a microservices-oriented framework with event-driven processing to segregate ingress, fan-out, and delivery stages. Ingress events from upstream services are ingested via an API gateway and enqueued in a distributed message broker. Fan-out logic expands events according to user subscriptions or preferences, with subsequent routing to channel-specific workers for delivery. Preferences and tracking data reside in sharded databases, supplemented by caching for performance. Monitoring integrates metrics for throughput, latency, and error rates to enable auto-scaling.
To depict this structure visually, the following diagram illustrates a scalable notification service architecture:
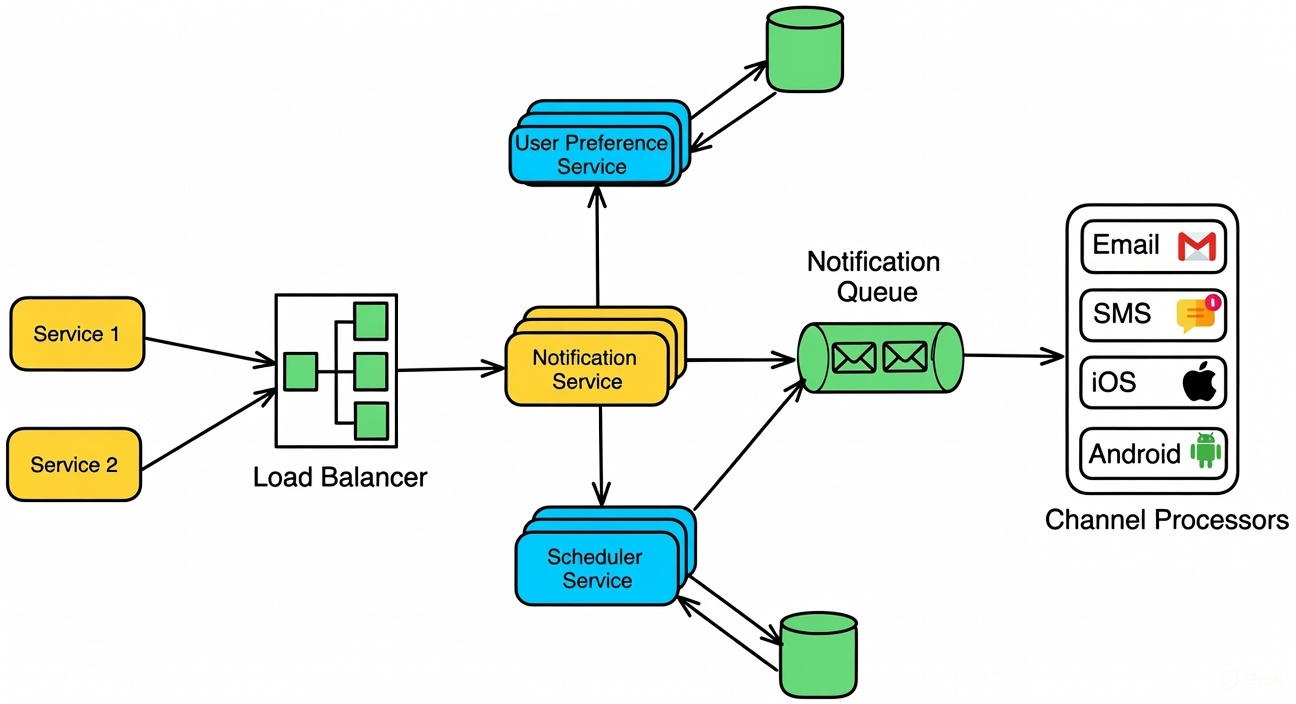
Core Design Decisions
Fan-out Strategy
- Fan-out on Write (used here): Expand recipients immediately → immediate consistency, but high write amplification during blasts.
- Preferred for real-time and when recipient list is manageable.
- Fan-out on Read: Store event once, users pull via WebSocket or polling → used by Facebook for news feed.
Hybrid: Real-time → fan-out on write; Marketing → store event + schedule batch job to fan-out.
User Preferences & Rate Limiting
- Preferences stored in DynamoDB/Cassandra with TTL for temporary opt-outs.
- On send: Check preferences → if blocked, drop silently or queue for later.
- Per-user rate limit via distributed token bucket (Redis) to prevent spam.
Templating & Personalization
- Templates in S3 or database with Handlebars/Mustache syntax.
- Producer service renders template per user (or per segment for batch).
Delivery Reliability
- Idempotency key per notification
- Workers retry with exponential backoff (max 7 days for push)
- APNs/FCM feedback loops for invalid tokens → update preferences
- Dead Letter Queue for permanent failures
Real-Time Delivery
- WebSocket connections sharded by user_id
- On notification → route to user’s connected server via Redis Pub/Sub or Kafka
Detailed Flow Example: Ride Completion Notification (Uber-like)
Ride service emits “ride.completed” event with {ride_id, user_id, driver_id}
Producer receives → looks up templates + user preferences
Preference check: User wants push + email, driver wants only push
Fanout creates two notifications:
User: “Your ride with Alice has ended. Rate your experience!”
Driver: “Ride completed. Earnings: $23.50”
Real-time queue → Push Workers → FCM/APNs → devices
Tracking workers record delivery/open events → ClickHouse
Scaling and Optimization Summary for Notification Service Architecture
The provided text appears to represent a condensed summary of scaling strategies and optimizations for key components within a scalable notification service system. This summary outlines the technologies employed, approaches to scaling, and specific optimizations to enhance performance, reliability, and efficiency. Such a framework is essential for handling high-throughput operations, such as fan-out notifications to millions of users, while maintaining low latency and cost-effectiveness.
To present this information clearly, I have reformatted it into a structured table for ease of reference. Each row details a component, its underlying technology, the primary scaling strategy, and key optimizations. Following the table, I provide a concise explanation of each component’s role and rationale.
| Component | Technology | Scaling Strategy | Key Optimization |
|---|---|---|---|
| Producer/Fanout | Stateless .NET/Java services | Auto-scale on CPU/queue lag | Batch preference lookups |
| Queue | Kafka (partitioned by user_id hash) | Add brokers | Separate partitions for priority |
| Workers | Kubernetes pods per channel | HPA on queue depth | Connection pooling to APNs/FCM |
| Preferences DB | DynamoDB/Cassandra | Sharded by user_id | Cache hot users in Redis |
| WebSocket | Socket.io cluster + Redis adapter | Horizontal pods | Sticky sessions via consistent hash |
Explanation of Components
- Producer/Fanout: This component handles the initial ingestion and expansion of notification events to targeted recipients. Utilizing stateless services in .NET or Java ensures that instances can be easily replicated without maintaining session data. Scaling is automated based on CPU utilization or queue backlog to manage sudden spikes in event volume. The key optimization involves batching user preference queries, which reduces database load and accelerates processing by grouping similar operations.
- Queue: Apache Kafka serves as the distributed message broker, with partitions hashed by user ID to distribute load evenly and enable parallel processing. Scaling is achieved by adding more broker nodes as throughput increases. Prioritizing messages through separate partitions allows critical notifications (e.g., real-time alerts) to be processed ahead of lower-priority ones, improving overall system responsiveness.
- Workers: These are responsible for delivering notifications via specific channels (e.g., push, email). Deployed as Kubernetes pods dedicated per channel, they allow independent scaling. Horizontal Pod Autoscaling (HPA) adjusts the number of pods based on queue depth metrics, ensuring resources match demand. Connection pooling to services like Apple Push Notification service (APNs) or Firebase Cloud Messaging (FCM) minimizes overhead from repeated connections, enhancing efficiency during high-volume deliveries.
- Preferences DB: User preferences (e.g., opt-ins, Do-Not-Disturb settings) are stored in a NoSQL database like Amazon DynamoDB or Apache Cassandra, sharded by user ID for distributed access and to avoid hotspots. Caching frequently accessed (“hot”) user data in Redis reduces latency for repeated queries, as it serves data from memory rather than disk.
- WebSocket: This facilitates real-time bidirectional communication for live notifications. A Socket.io cluster integrated with a Redis adapter enables pub/sub messaging across nodes. Scaling occurs through horizontal addition of pods to handle more connections. Sticky sessions, implemented via consistent hashing, ensure that a user’s connection remains with the same server, preserving context and reducing reconnection overhead.
This structured approach aligns with best practices in distributed systems, drawing from real-world implementations to achieve high availability and performance under varying loads. If additional details or expansions on any component are required, please provide further specifications.
Performance in Practice (2025)
- Instagram: >1B notifications/day
- WhatsApp: 150B+ messages/day
- AWS SNS: 30K+ messages/sec sustained in high-throughput mode
This design attains sub-second real-time delivery for essential notifications while proficiently managing extensive marketing initiatives, establishing it as the prevailing paradigm adopted by principal consumer applications in 2025.



