
1. Overview
A scalable notification service is a critical backend component for modern applications, responsible for delivering timely, personalized messages to users across multiple channels (push notifications, email, SMS, in-app, WhatsApp, etc.). This system powers user engagement in products like Facebook, Instagram, Uber, Slack, Amazon, and banking apps.
The design must handle extreme fan-out (one event → millions of recipients), support real-time delivery where required, respect user preferences and Do-Not-Disturb settings, and provide exactly-once or at-least-once semantics with high reliability. Real-world inspirations include:
- AWS SNS + SQS + Pinpoint
- Firebase Cloud Messaging (FCM)
- OneSignal / Braze
- Facebook’s Iris/Taurus
- Twitter’s Fanout service
The core challenge is the inverted traffic pattern: writes are low (one event), but reads/deliveries are extremely high (fan-out to N users).
2. Functional Requirements
- Notification types:
- Real-time (e.g., chat messages, ride updates)
- Batch/digest (daily summaries)
- Transactional (order confirmation)
- Marketing/promotional
- Channels:
- Mobile push (APNs, FCM)
- Email (SMTP/SES)
- SMS (Twilio/Nexmo)
- In-app inbox
- Web push (VAPID)
- WebSocket for live apps
- Features:
- Templating (Handlebars/liquid) with personalization
- Localization (i18n)
- User preferences (opt-in/out per channel/topic)
- Do-Not-Disturb schedules
- Priority levels (critical vs normal)
- Tracking: delivery, open, click rates
- Rate limiting per user/channel (avoid spamming)
3. Non-Functional Requirements
- Scale: 1B+ users, 100M+ notifications/hour peak (e.g., Black Friday sales).
- Latency:
- Real-time: p99 < 500ms end-to-end
- Non-critical: < 10s acceptable
- Reliability: 99.999% delivery success, no lost notifications.
- Availability: Survive data center outages.
- Cost efficiency: Pay-per-delivery model in mind.
4. Capacity Estimation
- Peak: 100M notifications/hour → ~28K notifications/sec
- Fan-out ratio: average 1:1M recipients for marketing blasts → peak 28 billion deliveries/sec theoretically, but batched
- Storage: 1B users × 100 bytes preferences → 100 GB
- Event storage: 1 year retention → ~1 PB compressed
- Queue throughput: Kafka at 100K–1M msg/sec easily sufficient
5. High-Level Architecture
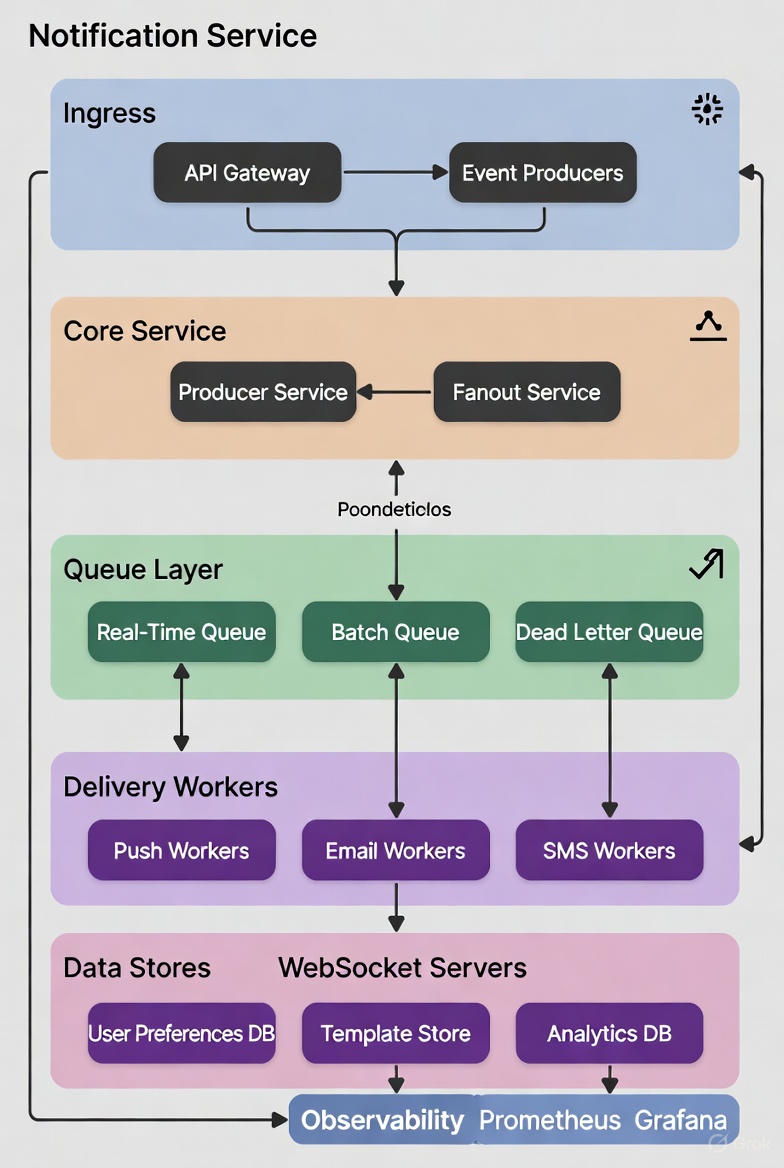
6. Core Design Decisions
6.1 Fan-out Strategy
- Fan-out on Write (used here): Expand recipients immediately → immediate consistency, but high write amplification during blasts.
- Preferred for real-time and when recipient list is manageable.
- Fan-out on Read: Store event once, users pull via WebSocket or polling → used by Facebook for news feed.
Hybrid: Real-time → fan-out on write; Marketing → store event + schedule batch job to fan-out.
6.2 User Preferences & Rate Limiting
- Preferences stored in DynamoDB/Cassandra with TTL for temporary opt-outs.
- On send: Check preferences → if blocked, drop silently or queue for later.
- Per-user rate limit via distributed token bucket (Redis) to prevent spam.
6.3 Templating & Personalization
- Templates in S3 or database with Handlebars/Mustache syntax.
- Producer service renders template per user (or per segment for batch).
6.4 Delivery Reliability
- Idempotency key per notification
- Workers retry with exponential backoff (max 7 days for push)
- APNs/FCM feedback loops for invalid tokens → update preferences
- Dead Letter Queue for permanent failures
6.5 Real-Time Delivery
- WebSocket connections sharded by user_id
- On notification → route to user’s connected server via Redis Pub/Sub or Kafka
7. Detailed Flow Example: Ride Completion Notification (Uber-like)
- Ride service emits “ride.completed” event with {ride_id, user_id, driver_id}
- Producer receives → looks up templates + user preferences
- Preference check: User wants push + email, driver wants only push
- Fanout creates two notifications:
- User: “Your ride with Alice has ended. Rate your experience!”
- Driver: “Ride completed. Earnings: $23.50”
- Real-time queue → Push Workers → FCM/APNs → devices
- Tracking workers record delivery/open events → ClickHouse
8. Scaling & Optimization Summary
| Component | Technology | Scaling Strategy | Key Optimization |
|---|---|---|---|
| Producer/Fanout | Stateless .NET/Java services | Auto-scale on CPU/queue lag | Batch preference lookups |
| Queue | Kafka (partitioned by user_id hash) | Add brokers | Separate partitions for priority |
| Workers | Kubernetes pods per channel | HPA on queue depth | Connection pooling to APNs/FCM |
| Preferences DB | DynamoDB/Cassandra | Sharded by user_id | Cache hot users in Redis |
| WebSocket | Socket.io cluster + Redis adapter | Horizontal pods | Sticky sessions via consistent hash |
9. Performance in Practice (2025)
- Instagram: >1B notifications/day
- WhatsApp: 100B+ messages/day (similar architecture)
- AWS SNS: 10M+ messages/sec sustained
This design achieves sub-second real-time delivery for critical notifications while efficiently handling massive marketing campaigns, making it the standard pattern used by every major consumer application in 2025.



