
Abstract
In the realm of distributed systems, achieving horizontal scalability while maintaining the reliability of a battle-tested relational database like MySQL presents formidable challenges. YouTube, the world’s premier video-sharing platform, exemplifies this triumph through its development of Vitess—an open-source database clustering system designed specifically to extend MySQL’s capabilities for internet-scale workloads. Originally conceived to address YouTube’s explosive growth from a fledgling startup to a service supporting over 2.49 billion monthly active users, Vitess introduces a sophisticated abstraction layer that simplifies sharding, query routing, and topology management. This white paper delves into the historical context of YouTube’s database evolution, the inherent limitations of vanilla MySQL at scale, and the architectural innovations of Vitess. By examining its core components—VTGate, VTTablet, VTctld, and the topology service—we elucidate how Vitess mitigates replication lag, ensures query safety, and enables seamless horizontal scaling. Drawing on case studies, performance metrics, and implementation insights, this document provides a comprehensive blueprint for organizations seeking to deploy resilient, high-throughput database infrastructures. Ultimately, Vitess not only propelled YouTube to unprecedented heights but also democratized scalable MySQL deployments for enterprises worldwide.
Introduction
The inception of YouTube traces back to 2005, when three former PayPal engineers—Chad Hurley, Steve Chen, and Jawed Karim—embarked on an ambitious venture initially aimed at creating a video-dating platform. Their prototype, however, quickly revealed flaws in the business model, prompting a strategic pivot toward a more versatile video-sharing service. The first video uploaded to the platform, “Me at the zoo,” marked the beginning of an era defined by exponential user adoption. By 2006, Google had acquired YouTube for $1.65 billion, recognizing its potential to redefine online media consumption.
At its core, YouTube’s early architecture relied on MySQL, a robust open-source relational database management system (RDBMS), to store essential metadata such as video titles, descriptions, user profiles, and interaction logs. MySQL’s ACID compliance, mature ecosystem, and ease of use made it an ideal choice for a startup operating under resource constraints. As user numbers surged—reaching one billion monthly active users by 2013 and escalating to 2.49 billion by 2023—the platform’s database layer faced existential pressures. This growth transformed YouTube from the second most visited website globally into a digital behemoth handling petabytes of data and tens of millions of queries per second (QPS).
To sustain this trajectory, YouTube engineers implemented leader-follower replication, a standard MySQL scaling technique where a primary (leader) instance handles writes, and secondary (follower) instances replicate data for read-heavy workloads. While effective in theory, this topology exposed MySQL’s single-threaded replication limitations, leading to lag under high write throughput. Subsequent mitigations, such as binary log caching, provided temporary relief but unearthed deeper issues: sharding complexities, data staleness, and vulnerability to query overloads.
Recognizing the need for a unified solution, YouTube developed Vitess in 2011, a Go-based orchestration layer that abstracts MySQL’s operational intricacies. Vitess does not supplant MySQL but enhances it, enabling horizontal scaling without necessitating wholesale application rewrites. This white paper systematically explores these dynamics, offering actionable insights for database practitioners navigating similar scaling imperatives.
Challenges in Scaling MySQL for Internet-Scale Applications
MySQL’s ubiquity stems from its balance of performance, cost-effectiveness, and community support. However, as workloads intensify—particularly in read-write intensive environments like video platforms—its monolithic nature reveals critical bottlenecks. YouTube’s experience underscores three primary challenges: replication inefficiencies, sharding intricacies, and operational safeguards.
Replication Inefficiencies
In a leader-follower topology, the leader processes all writes, streaming changes via binary logs to followers. MySQL’s default single-threaded replication, however, serializes these updates, creating bottlenecks during peak loads. For YouTube, explosive growth meant write operations—such as video uploads and metadata updates—overwhelmed followers, resulting in replication lag exceeding seconds. This lag manifested as stale reads, eroding user experience in time-sensitive features like comment feeds or recommendation engines.
A partial workaround involved preloading binary log events into an in-memory cache, rendering replication memory-bound and accelerating synchronization. While this alleviated immediate pressure, it introduced memory overhead and failed to address underlying throughput constraints. At scale, even optimized replication could not sustain the platform’s trajectory toward billions of daily interactions.
Sharding Complexities
As datasets ballooned beyond terabytes, vertical scaling via larger hardware proved unsustainable due to diminishing returns and single points of failure. Horizontal scaling necessitated sharding—partitioning data across multiple MySQL instances based on keys like user IDs or video hashes. However, MySQL lacks native sharding support, thrusting the burden onto application logic.
Developers must manually determine target shards for queries, complicating joins and transactions that span partitions. Cross-shard operations, common in analytical workloads, become infeasible without custom orchestration, increasing development overhead and downtime risks during resharding. YouTube’s early sharding experiments highlighted these pain points: application code swelled with shard-awareness logic, elevating the probability of errors and maintenance burdens.
Operational Safeguards and Performance Risks
Beyond structural limitations, operational resilience posed acute challenges. Long-running queries could monopolize resources, starving concurrent operations, while unchecked connection pools risked exhausting MySQL’s thread limits—often capped at 1,000–10,000 per instance. Read-after-write consistency further complicated matters; applications required conditional routing to the leader for fresh data, embedding staleness detection into business logic.
These issues compounded during traffic spikes, such as viral video launches, potentially cascading into outages. YouTube’s pre-Vitess era witnessed intermittent downtime, underscoring the imperative for automated protections like query timeouts, connection throttling, and load balancing.
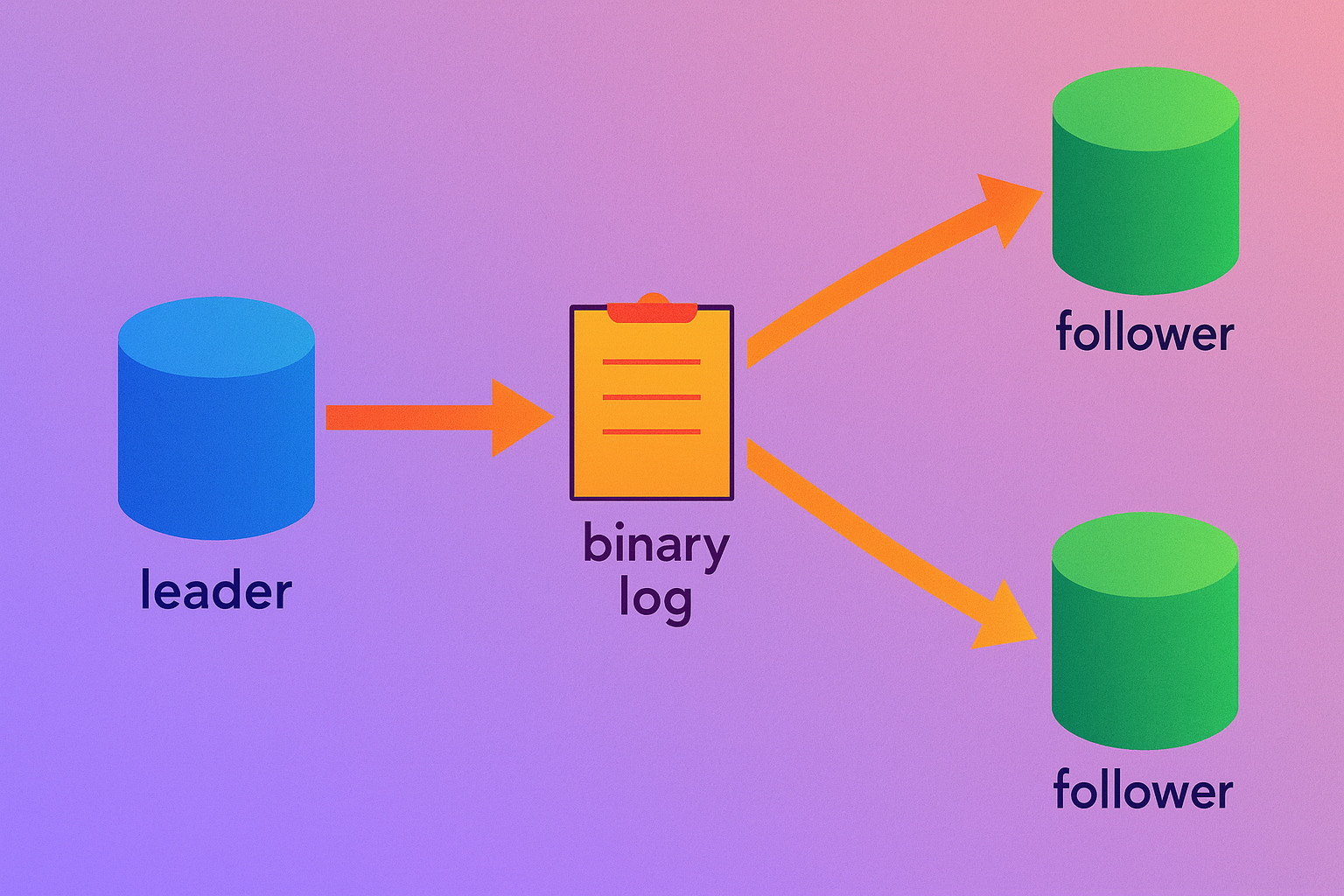
Figure 1: Leader-Follower Replication Topology in MySQL.
The Genesis and Design Principles of Vitess
Vitess emerged from YouTube’s internal necessity, formalized in 2011 by engineers Sugu Sougoumarane and Mike Solomon. As detailed in their seminal USENIX LISA presentation, Vitess encapsulates ad-hoc processes honed over years of MySQL wrangling, repackaged as a cohesive, extensible framework. Implemented in Go for its concurrency primitives and low-latency performance, Vitess adheres to three pillars: minimal MySQL modifications, externalized control planes, and declarative scaling semantics.
Unlike proprietary clustering solutions (e.g., MySQL Group Replication), Vitess prioritizes loose coupling, allowing operators to leverage commodity hardware and existing MySQL expertise. It supports both MySQL and MariaDB, with pluggable topology services like ZooKeeper or etcd. At its heart, Vitess transforms a fleet of MySQL shards into a logical monolith, shielding applications from distribution complexities.
Key design tenets include:
- Shard-Agnostic Queries: Applications interact via a unified SQL interface, oblivious to underlying partitions.
- Automated Orchestration: Failovers, backups, and resharding occur online, minimizing human intervention.
- Fail-Safe Mechanisms: Built-in query rewriting, caching, and throttling prevent overloads.
- Eventual Consistency: Prioritizes availability over strict ACID across shards, aligning with YouTube’s read-dominant patterns.
These principles enabled Vitess to evolve from an internal tool to a CNCF-graduated project, adopted by Slack, GitHub, and PlanetScale.
Vitess Architecture: Components and Interactions
Vitess’s architecture comprises four interlocking layers: query serving (VTGate), per-shard agents (VTTablet), control plane (VTctld), and metadata store (Topology Service). This modular design facilitates independent scaling and fault isolation, as depicted in the high-level overview.
VTGate: The Stateless Query Router
VTGate serves as the ingress proxy, emulating a monolithic MySQL server over the MySQL wire protocol. Stateless by design, multiple VTGate instances can be load-balanced via tools like Envoy or HAProxy, ensuring horizontal scalability. Upon receiving a query, VTGate parses the SQL, resolves the target keyspace and shard(s) using the topology service, and dispatches to appropriate VTTablets.
Core functionalities include:
- Shard Mapping: Employs a configurable sharding scheme (e.g., range-based or hash-modulo) to route DML/DDL statements.
- Connection Pooling: Maintains a bounded pool per backend, mitigating connection storms—critical for YouTube’s 100,000+ concurrent clients.
- Query Planning: Supports scatter-gather for read queries across shards, with optional aggregation (e.g., SUM over distributed results).
- Transaction Management: Enforces single-shard transactions, aborting multi-shard attempts to preserve simplicity.
In production, VTGate caches topology metadata locally, reducing latency to sub-milliseconds. It also enforces quotas, such as transaction limits (e.g., 10 per second per connection), to safeguard against abuse.
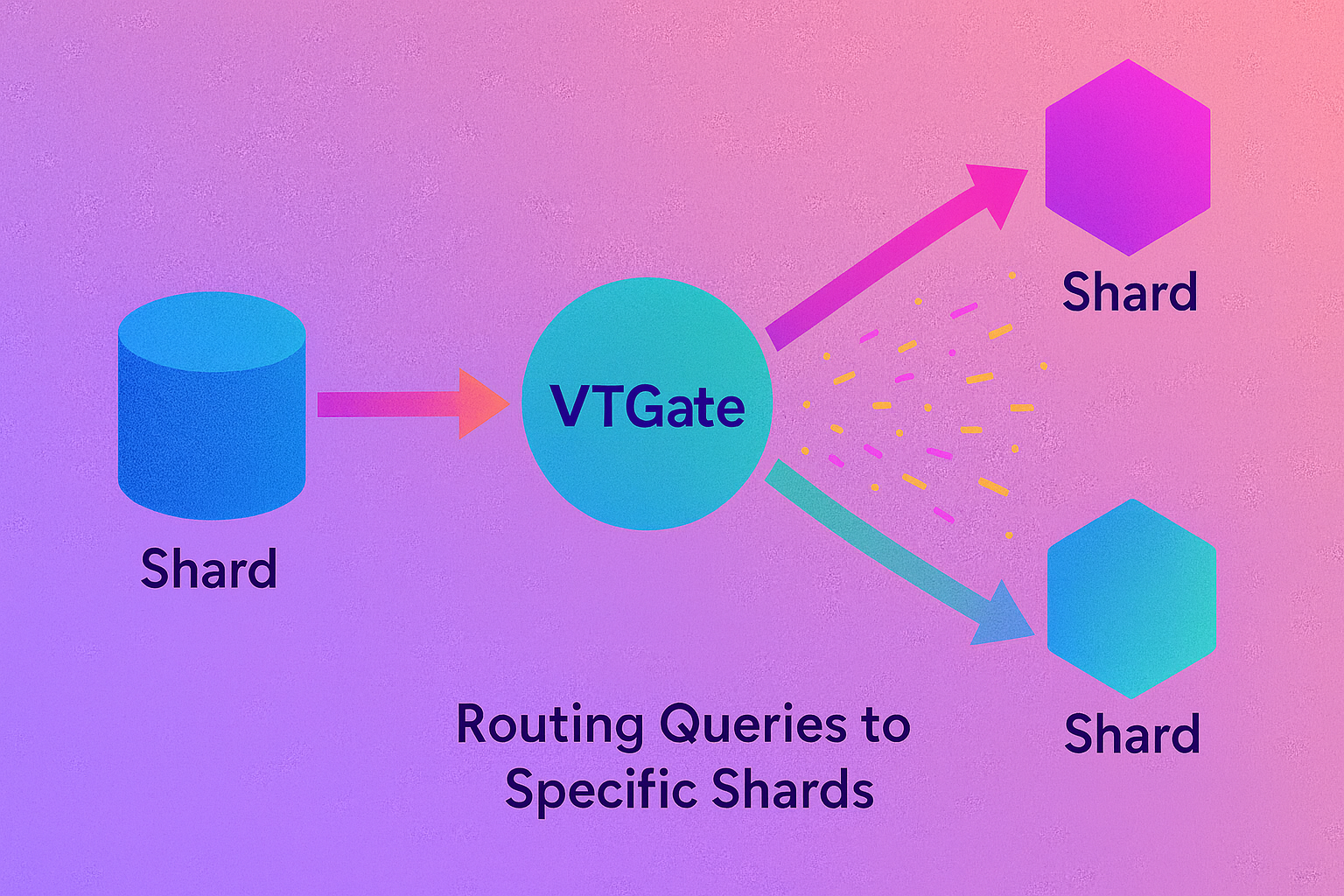
Figure 2: VTGate Routing Queries to Specific Shards
VTTablet: The Per-Instance Sidecar
Co-located with each MySQL shard as a sidecar process, VTTablet acts as a thin proxy and manager, insulating the database from direct application exposure. It streams binary logs for real-time change capture, enabling features like update streams for denormalized caches.
Key responsibilities encompass:
- Query Execution: Rewrites unsafe queries (e.g., appending LIMIT to SELECT *), applies safeguards (e.g., row count caps), and executes via a pooled MySQL connector.
- Replication Oversight: Monitors health, promotes replicas during failovers, and handles semi-synchronous replication for durability.
- Backup and Recovery: Orchestrates point-in-time recovery using XtraBackup, storing snapshots in object storage like GCS.
- Health Checks: Exposes Prometheus metrics for observability, including QPS, lag, and error rates.
VTTablet’s streaming replication decouples it from MySQL’s native mechanisms, allowing custom buffering to combat lag. In YouTube’s deployment, VTTablets process over 100 million events per second across thousands of shards.
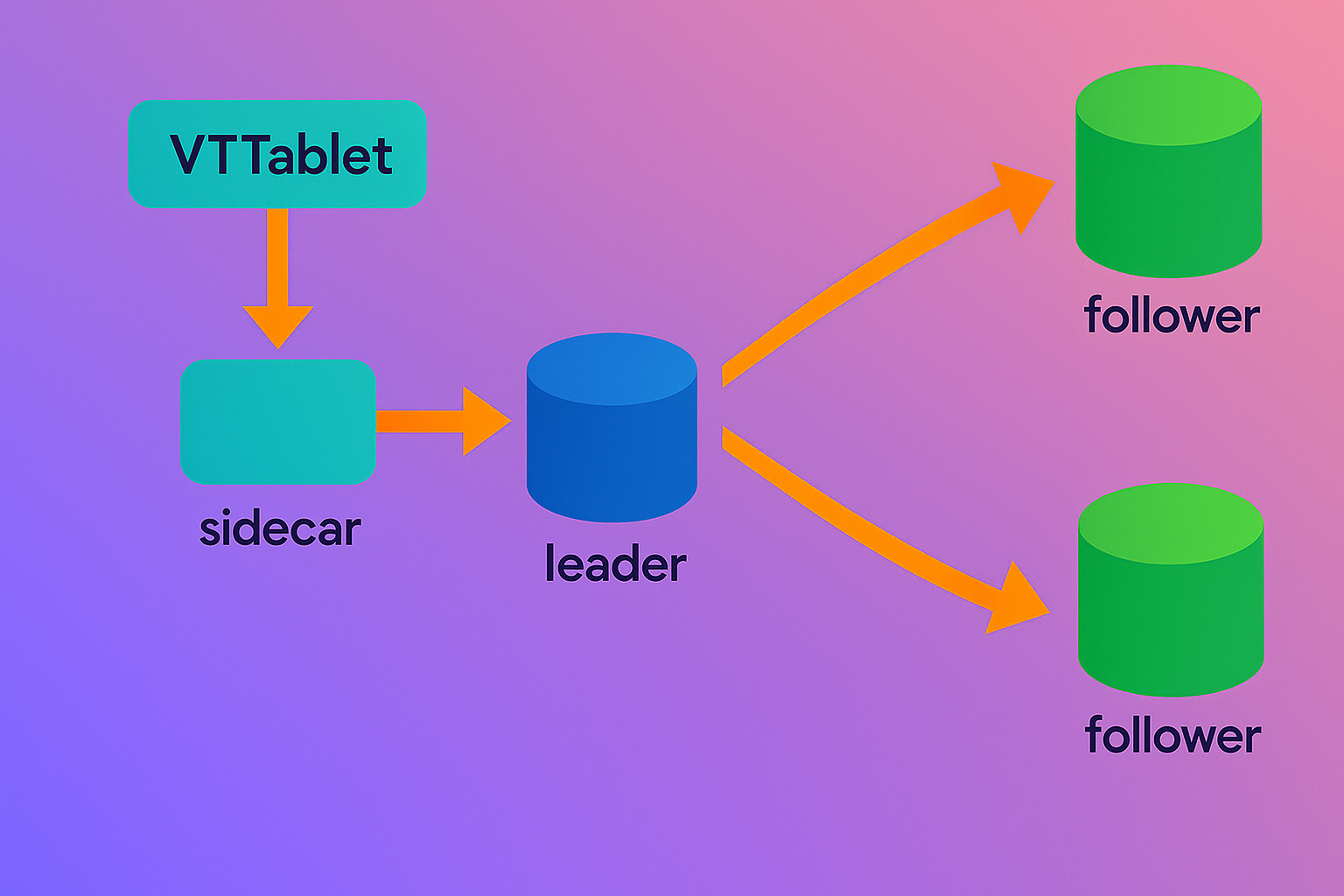
Figure 3: VTTablet Running as a Sidecar Server
VTctld: The Control Daemon
VTctld functions as the stateful controller, exposing an HTTP/gRPC API for administrative tasks. It aggregates topology data, executes workflows like resharding (VReplication for data movement), and coordinates cluster-wide actions such as schema migrations.
Operators interact via CLI tools (vtctl) or web UIs, issuing commands like vtctl Reshard to split shards online. VTctld ensures atomicity through locking in the topology service, preventing concurrent modifications.
Topology Service: Metadata Backbone
A distributed key-value store (typically ZooKeeper) persists cluster state: keyspaces, shards, tablet roles, and replication graphs. VTGate and VTctld query this for routing and orchestration, with local caching for resilience. ZooKeeper’s consensus protocol guarantees strong consistency, though etcd alternatives offer Kubernetes-native integration.
Interactions form a feedback loop: Applications query VTGate → Routes to VTTablet → Executes on MySQL → Logs changes to topology via VTctld. This closed system supports dynamic resharding—e.g., splitting a hot shard without downtime—via filtered replication.
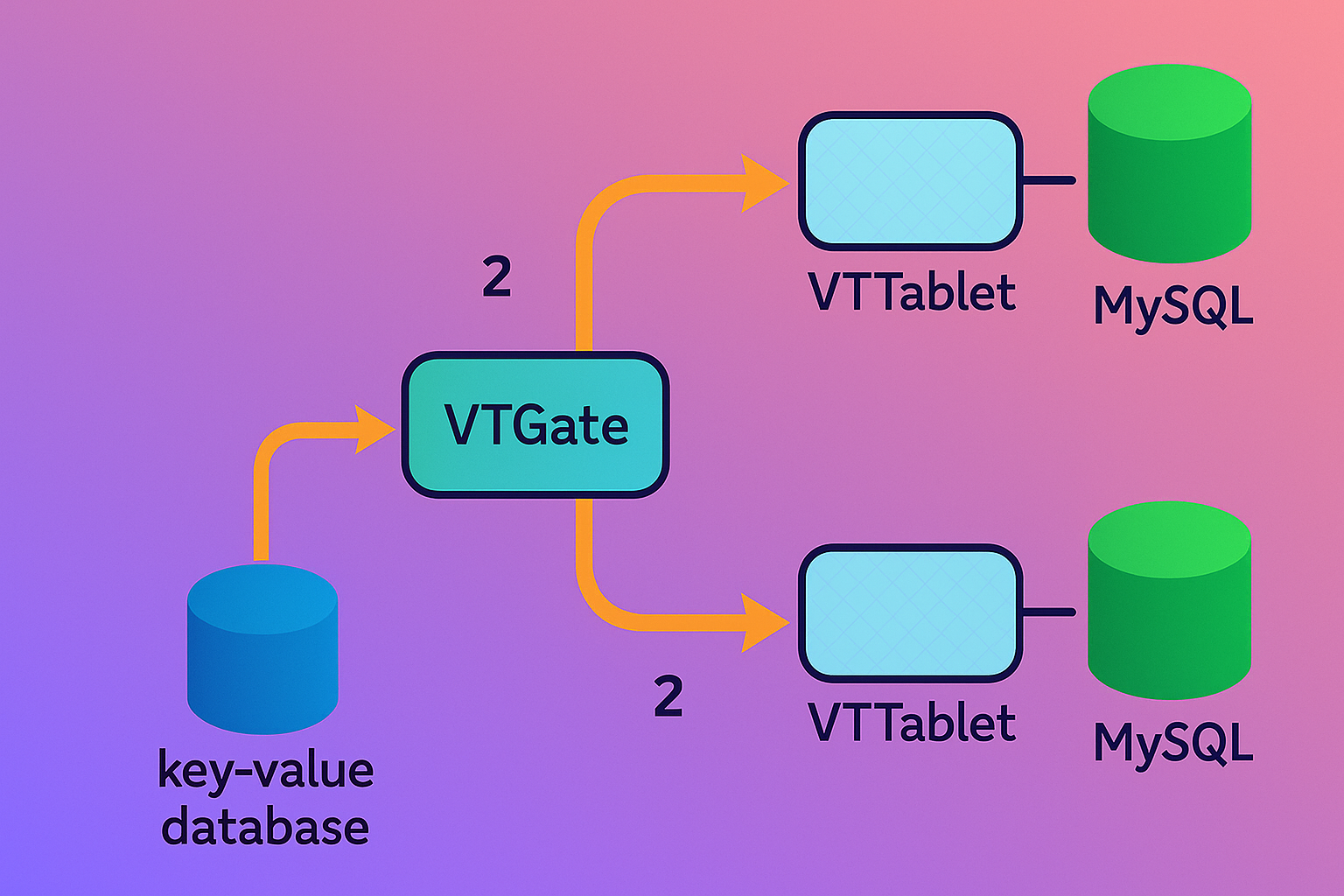
Figure 4: Key-Value Database Storing Meta Information
Implementation and Deployment Considerations
Vitess’s Go implementation leverages goroutines for concurrent query handling, achieving low-latency multiplexing—up to 50,000 connections per VTGate instance on modest hardware. The codebase emphasizes readability and testability, with over 90% unit test coverage. Deployment typically integrates with Kubernetes via the Vitess Operator, automating pod orchestration and rolling updates.
YouTube’s rollout began in 2011 with non-critical keyspaces, graduating to core tables by 2012. Key adaptations included custom query rewriters for video-specific patterns (e.g., denormalizing views counts) and integration with Borg for cell-based isolation—geographically distributed clusters insulated against failures.
Performance benchmarks from early adopters reveal 10x connection efficiency gains and sub-10ms p99 latencies at 1 million QPS. Resharding workflows, once manual multi-day ordeals, now complete in hours with zero data loss.
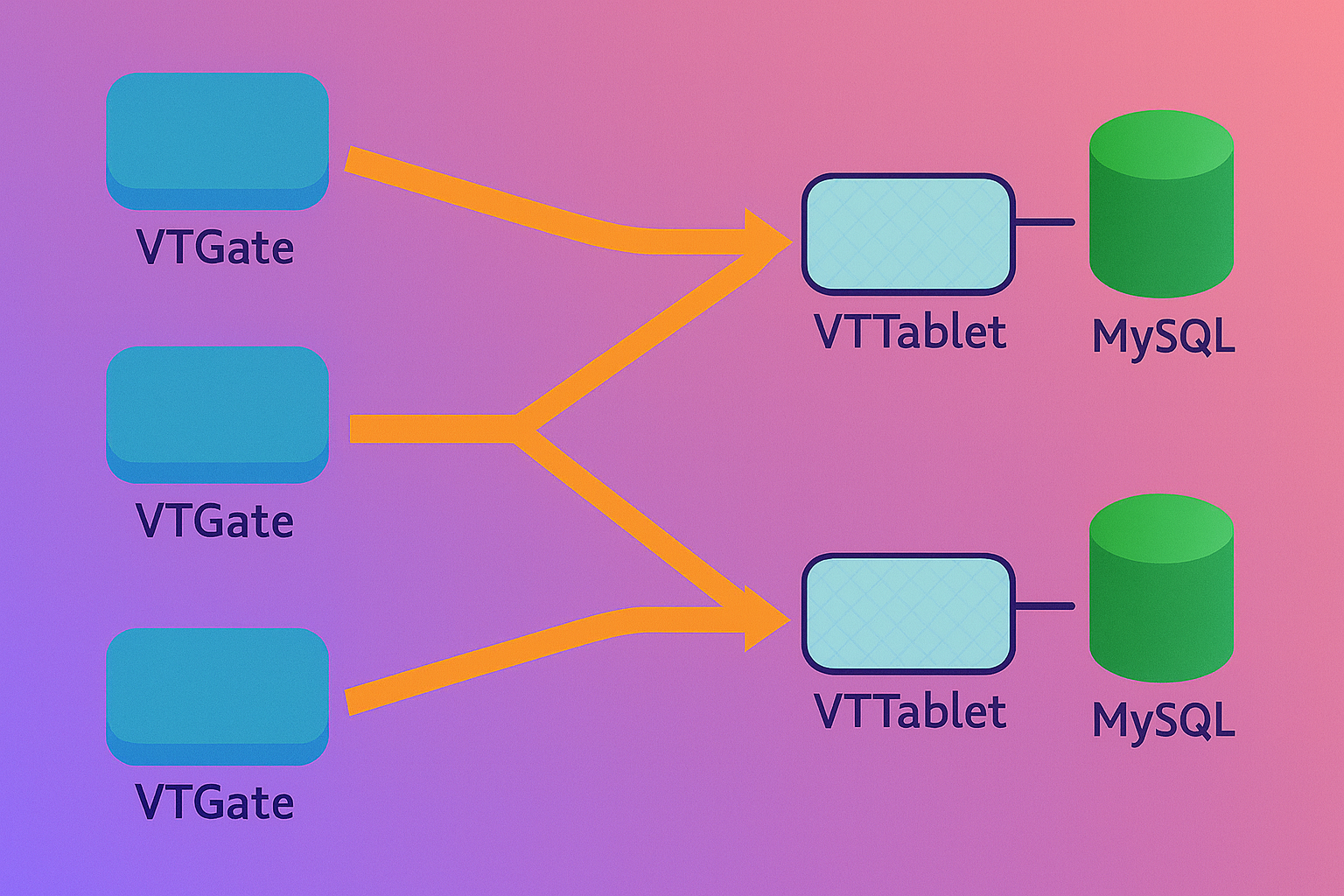
Figure 6: Scaling with Many VTGate Servers.
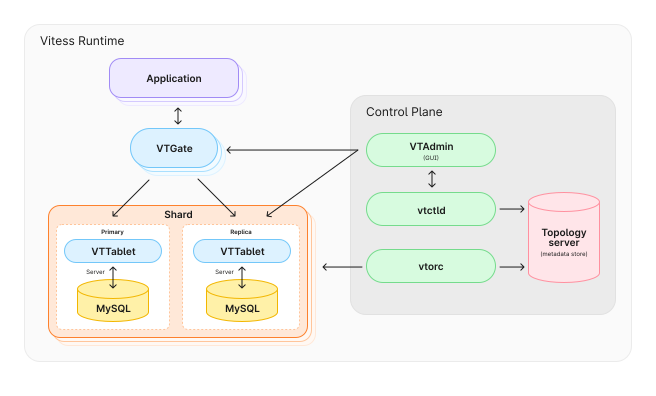
Figure 7: High-Level Architecture of Vitess (source: https://vitess.io/)
Case Study: YouTube’s Vitess Deployment
YouTube’s Vitess odyssey exemplifies pragmatic innovation. By 2013, the platform processed 6 billion views daily, straining a pre-sharded MySQL fleet. Vitess’s introduction halved replication lag, enabling consistent global reads. Today, it orchestrates over 10,000 MySQL instances across 20+ cells, serving 2.49 billion users with 99.99% uptime.
Metrics highlight efficacy: Peak QPS exceeds 50 million, with VTGate handling 90% of traffic statelessly. Resharding events—triggered by hot spots in user-generated content—average 4 hours, versus weeks pre-Vitess. Cost savings stem from commodity servers, reducing per-QPS expenses by 40%.
Challenges persisted: Initial ZooKeeper bottlenecks necessitated zkocc (insulated clients), and multi-region latency required cell-aware routing. Lessons include prioritizing observability (e.g., via Grafana dashboards) and iterative sharding schemes.
Benefits, Limitations, and Lessons Learned
Vitess confers manifold advantages: Simplified operations via automation, enhanced security through query sanitization, and ecosystem compatibility (e.g., with ORMs like SQLAlchemy). For YouTube, it preserved MySQL’s familiarity while unlocking NoSQL-like scalability.
Limitations include single-shard transaction confines—unsuited for polyglot persistence needs—and ZooKeeper’s operational overhead. Mitigations involve hybrid architectures, blending Vitess with Cassandra for analytics.
Key takeaways:
- Embrace Abstractions: Layered systems decouple evolution paces.
- Fail Fast, Recover Faster: Built-in safeguards outperform reactive firefighting.
- Community Leverage: Open-sourcing accelerates refinement, as evidenced by 500+ contributors.
Conclusion
YouTube’s mastery of MySQL scaling via Vitess stands as a testament to engineered resilience amid hypergrowth. By addressing replication, sharding, and protection head-on, Vitess not only sustained 2.49 billion users but redefined database orchestration for the cloud-native era. Organizations confronting analogous pressures—be they e-commerce giants or social platforms—stand to gain from its principles: modularity, automation, and relentless iteration. As data volumes inexorably rise, Vitess illuminates a path where legacy systems evolve into scalable powerhouses, ensuring innovation outpaces entropy.



