
Introduction
Client-server architecture is a foundational model in distributed computing, underpinning the design of modern software systems, including web applications, enterprise solutions, and networked services. This architecture delineates the roles of clients and servers, where clients initiate requests, and servers respond with the requested services or data. Understanding this model is critical for system design interviews, as it forms the basis for scalable, reliable, and efficient system architectures. This comprehensive exploration covers the fundamentals of client-server models, including the request-response pattern, variations, advantages, challenges, and real-world applications. The content is enriched with detailed explanations, historical context, and strategic considerations to provide a thorough understanding suitable for an extended study session.
Fundamentals of Client-Server Architecture
Definition and Core Components
Client-server architecture is a distributed system model where tasks are divided between service providers (servers) and service requesters (clients). The architecture is characterized by a clear separation of concerns:
- Client: A device or software entity (e.g., web browser, mobile app) that requests services or resources. Clients are typically user-facing, handling input, display, and interaction logic.
- Server: A system or software entity that provides services or resources (e.g., data, computation, storage) in response to client requests. Servers are designed to handle multiple concurrent requests, often with enhanced processing and storage capabilities.
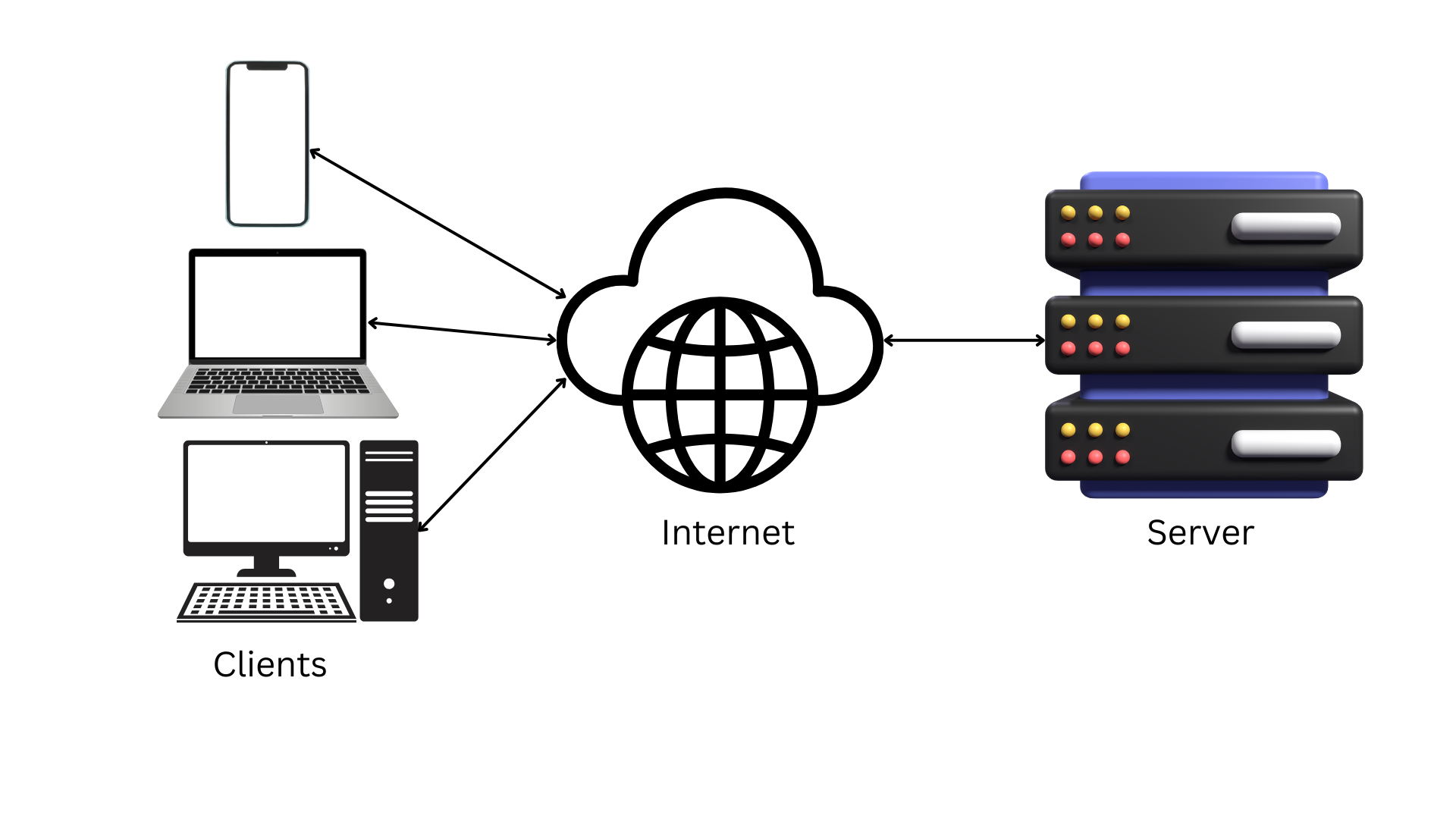
This division allows for specialization, where clients focus on user experience and servers manage backend operations. Communication occurs over a network, commonly using protocols like HTTP/HTTPS, TCP/IP, or others, depending on the application.
Historical Context
The concept of client-server architecture emerged with the advent of networked computing, tracing its roots to the 1980s. Early mainframe systems relied on centralized processing, with terminals acting as passive clients. The shift to distributed systems began with the introduction of personal computers and local area networks, enabling the client-server model. Key developments, such as the growth of the Internet in the 1990s and the rise of cloud computing in the 2000s, have expanded this architecture to global scales, shaping the digital infrastructure of today.
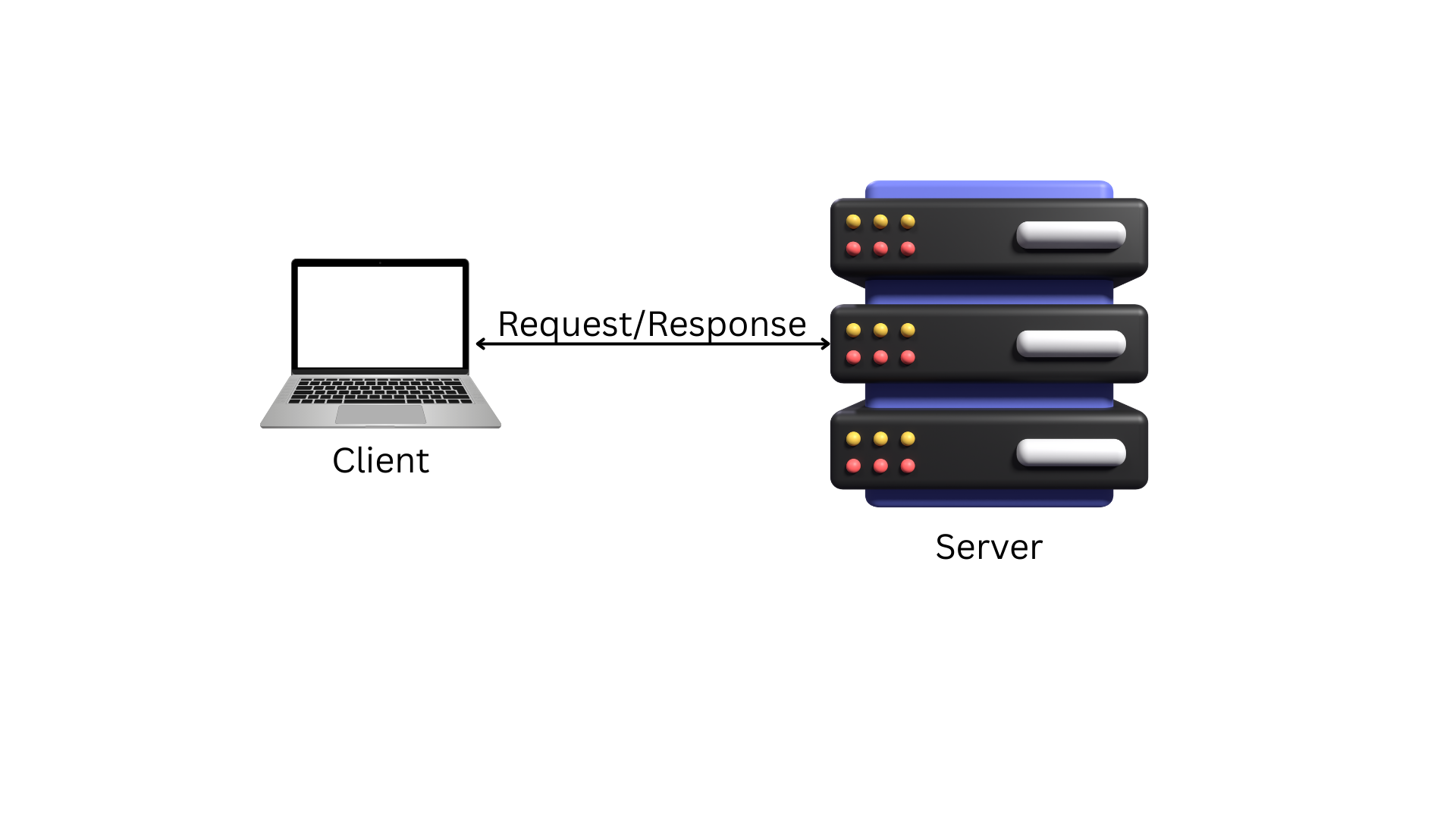
Request-Response Pattern
The request-response pattern is the cornerstone of client-server communication. This interaction follows a structured sequence:
- Request Initiation: The client sends a request to the server, specifying the desired action (e.g., retrieving data, updating a record) and any required parameters.
- Server Processing: The server processes the request, which may involve querying a database, performing computations, or interacting with other services.
- Response Delivery: The server returns a response to the client, containing the requested data, a confirmation, or an error message, typically formatted (e.g., JSON, XML).
This pattern is inherently synchronous in its basic form, meaning the client waits for the server’s response before proceeding. However, modern systems often incorporate asynchronous variants, such as callbacks or webhooks, to enhance responsiveness. For instance, in a web application, a user clicking a “search” button triggers a GET request, and the server responds with search results, illustrated by a flow from client UI to server API and back.
Variations of Client-Server Architecture
Two-Tier Architecture
In a two-tier architecture, the client and server are directly connected with minimal intermediaries. The client handles the presentation layer (UI), while the server manages the data layer (database and business logic). This model is common in early client-server applications, such as desktop-based accounting software, where the client queries a local server directly. Advantages include simplicity and reduced latency, but scalability is limited due to the tight coupling between client and server. This design is less flexible for distributed environments, often requiring significant reengineering as demands grow.
Three-Tier Architecture
The three-tier architecture introduces an additional layer, separating the application logic from the presentation and data layers. The tiers are:
- Presentation Tier: The client interface (e.g., web browser).
- Application Tier: The middle tier handling business logic and processing (e.g., API servers).
- Data Tier: The backend storage (e.g., databases).
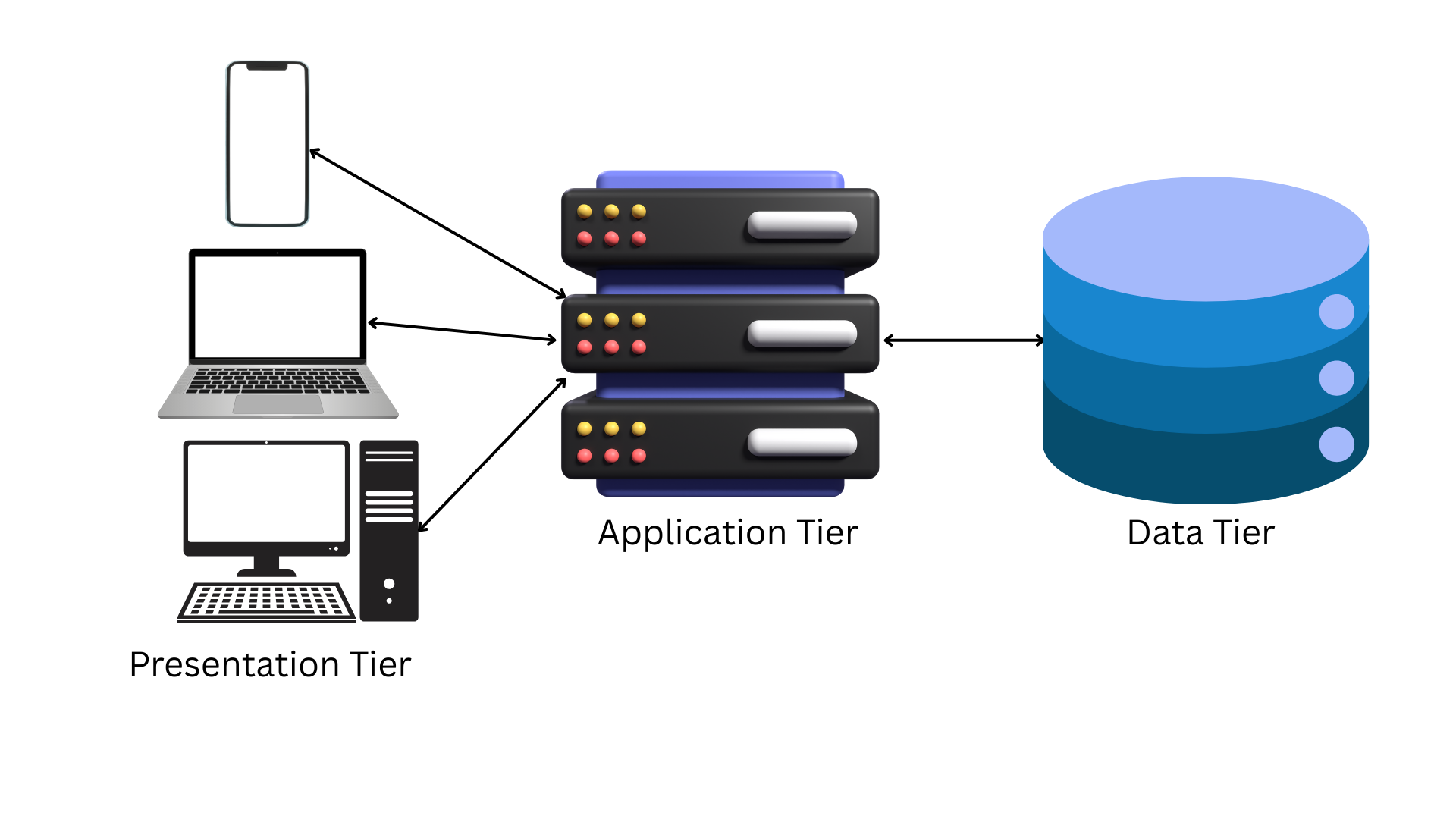
This model, prevalent in web applications like e-commerce platforms, enhances modularity and scalability. For example, an online store might have a frontend (client), an application server processing orders, and a database storing inventory. The separation allows independent scaling of each tier, such as adding more application servers to handle peak traffic, though it increases complexity in coordination and data consistency across layers.
N-Tier Architecture
N-tier architecture extends the three-tier model to multiple layers, often seen in large-scale systems. Each tier (e.g., presentation, business logic, data access, caching) can be distributed across different servers or regions. Modern cloud-based systems, such as those used by streaming services, employ N-tier designs, with separate layers for content delivery, recommendation engines, and user data. This flexibility supports high availability and fault tolerance, enabling failover mechanisms and load balancing. However, it requires sophisticated orchestration tools and strategies to manage inter-tier dependencies and ensure performance.
Advantages of Client-Server Architecture
Scalability
One of the primary advantages is scalability. Servers can be upgraded or replicated to handle increased load, while clients remain lightweight. Load balancers can distribute requests across multiple servers, ensuring performance during traffic spikes. This modularity allows organizations to scale specific components (e.g., database servers) without overhauling the entire system.
Centralized Management
Servers provide a central point for managing data, security, and updates. This centralization simplifies administration, as changes (e.g., security patches) can be applied at the server level rather than across all clients. It also facilitates backup and recovery processes, critical for data integrity in enterprise environments.
Enhanced Security
Security can be concentrated on the server, where access controls, encryption, and monitoring are implemented. Clients interact through secure channels (e.g., HTTPS), reducing exposure to vulnerabilities. This model supports role-based access, ensuring that sensitive data is protected at the server level.
Flexibility and Specialization
The separation of roles allows for specialized development. Clients can be optimized for user interfaces across devices (e.g., mobile, desktop), while servers focus on robust backend processing. This flexibility supports diverse applications, from real-time gaming to business analytics.
Challenges and Considerations
Single Point of Failure
The server represents a potential single point of failure. If it goes down, clients lose access unless redundancy (e.g., failover servers) is implemented. Designing for high availability, such as using clusters or geographic distribution, mitigates this risk but adds complexity.
Network Dependency
Performance relies on network stability and bandwidth. Latency or outages can disrupt communication, necessitating strategies like caching or offline modes for clients. In distributed systems, network partitioning can lead to consistency challenges, often addressed through eventual consistency models.
Complexity in Design
As architectures evolve from two-tier to N-tier, design complexity increases. Coordinating multiple tiers requires careful planning for data synchronization, load distribution, and error handling. This complexity can lead to higher development and maintenance costs.
Resource Utilization
Servers must handle concurrent requests, requiring significant resources (e.g., CPU, memory). Overloading can degrade performance, necessitating capacity planning and monitoring tools to predict and manage demand.
Real-World Applications
Web Applications
The World Wide Web exemplifies client-server architecture, with browsers as clients and web servers as providers. A user visiting an e-commerce site sends a request for product listings, and the server responds with HTML and data, often enriched with APIs for dynamic content. Content delivery networks (CDNs) enhance this model by caching static assets closer to users.
Enterprise Systems
Enterprise resource planning (ERP) systems, such as those used by large corporations, rely on client-server models. Clients access centralized servers for payroll, inventory, and customer management, with the three-tier architecture supporting modular updates and scalability.
Cloud Computing
Cloud providers like Amazon Web Services (AWS) and Microsoft Azure operate on client-server principles, where clients (e.g., applications, users) interact with cloud servers for storage, computation, and services. The N-tier approach enables global scalability, with regions and availability zones ensuring redundancy.
Internet of Things (IoT)
In IoT ecosystems, devices (clients) send sensor data to servers for processing and analysis. For instance, a smart thermostat communicates with a cloud server to adjust settings, leveraging the architecture’s ability to handle distributed, real-time interactions.
Strategic Considerations in System Design
Load Balancing and Redundancy
To address scalability and single-point-of-failure concerns, implement load balancers to distribute requests and redundant servers for failover. Strategies like round-robin or least-connections algorithms optimize resource use, while geographic redundancy ensures continuity during regional outages.
Caching and Performance Optimization
Caching frequently accessed data at the client or intermediate layers (e.g., CDNs) reduces server load and latency. Techniques like in-memory caching or edge computing enhance performance, particularly in high-traffic scenarios.
Security Implementation
Adopt a defense-in-depth approach, with server-side security (e.g., firewalls, intrusion detection) and client-side validation. Encryption of data in transit and at rest, along with regular security audits, is essential to protect against evolving threats.
Asynchronous Communication
For applications requiring real-time updates (e.g., chat apps), incorporate asynchronous models like WebSockets or message queues. This approach decouples request-response cycles, improving responsiveness and enabling event-driven designs.
Interview Preparation: Key Concepts to Master
Architectural Trade-Offs
Be prepared to discuss trade-offs between two-tier and N-tier models. For example, a two-tier system may suffice for small applications but lacks the scalability of an N-tier design for large-scale deployments. Highlight how these choices impact cost, maintenance, and performance. In a two-tier architecture, the direct connection between client and server simplifies initial development and reduces latency for small-scale systems, such as a local inventory management tool used by a single office. However, as user demand grows, this model struggles to accommodate increased traffic or data volume, often necessitating a complete redesign. The tight coupling limits flexibility, making it challenging to scale individual components independently, and maintenance becomes cumbersome as updates must propagate to both client and server simultaneously.
In contrast, an N-tier architecture offers greater scalability by distributing responsibilities across multiple layers, such as presentation, application, and data tiers. This modularity allows for targeted scaling—adding more application servers to handle peak loads or upgrading database servers for complex queries—without affecting the entire system. However, this comes at a higher initial cost due to the need for additional infrastructure, such as load balancers and inter-tier communication protocols. Maintenance also increases in complexity, requiring coordination across layers to ensure data consistency and performance. For instance, a global e-commerce platform might use an N-tier model to manage millions of users, but the cost of maintaining redundant servers and optimizing inter-tier latency must be justified against the two-tier simplicity for smaller operations.
Performance considerations further differentiate these models. Two-tier systems can offer lower latency in controlled environments due to direct communication, but they may bottleneck under heavy load, leading to degraded user experience. N-tier systems, while potentially introducing slight latency from inter-tier hops, leverage techniques like caching and load balancing to maintain performance at scale. In interviews, articulating these trade-offs—such as choosing a two-tier model for a startup with limited resources versus an N-tier model for a multinational enterprise—demonstrates a nuanced understanding of architectural decision-making. Candidates should also explore hybrid approaches, where a two-tier system evolves into an N-tier structure as requirements grow, highlighting adaptability as a key design principle.
Request-Response Optimization
Explain strategies to optimize the request-response cycle, such as reducing payload size, implementing compression, or using asynchronous calls. Provide examples, like minimizing JSON fields in API responses to enhance speed. Reducing payload size is a critical strategy, particularly for bandwidth-constrained environments like mobile networks. By minimizing the data returned in responses—such as excluding unnecessary fields like detailed metadata in a user profile API (e.g., returning only “name” and “email” instead of “name,” “email,” “address,” and “phone”)—the system reduces transmission time and server load. This approach requires careful API design, where endpoints are tailored to specific use cases, ensuring clients receive only essential data.
Implementing compression, such as GZIP or Brotli, further optimizes the cycle by shrinking the size of data packets before transmission. For instance, a JSON response containing a large dataset, such as a list of products, can be compressed to a fraction of its original size, significantly lowering latency, especially over high-latency connections. Servers must support compression, and clients must be configured to decompress, but the trade-off in CPU usage is often worthwhile for the bandwidth savings.
Asynchronous calls offer another layer of optimization, allowing clients to continue processing while awaiting server responses. This is particularly useful in scenarios involving long-running operations, such as image processing or database queries. For example, a client might initiate an asynchronous request to upload a file, receiving a task ID immediately, while the server processes the upload in the background and notifies the client via a webhook or polling mechanism. This reduces perceived wait times and improves user experience, though it requires robust state management to track asynchronous tasks.
Additional techniques include caching responses at the client or intermediate layers (e.g., using HTTP headers like “Cache-Control”) to avoid redundant requests, and implementing pagination or lazy loading for large datasets to limit the volume of data per response. In interviews, candidates can illustrate these strategies with a scenario, such as optimizing a weather app where compressing forecast data and using asynchronous updates for real-time alerts enhances performance, showcasing practical application of optimization principles.
Scalability and Fault Tolerance
Demonstrate knowledge of scaling techniques (e.g., horizontal scaling with additional servers) and fault tolerance (e.g., circuit breakers). Use diagrams to illustrate how load balancers and redundant servers maintain system availability. Horizontal scaling involves adding more servers to distribute the workload, a technique ideal for handling increased traffic. For example, during a product launch, an e-commerce site might deploy additional application servers behind a load balancer, which evenly distributes incoming requests using algorithms like round-robin or least-connections. This approach contrasts with vertical scaling (adding resources to a single server), which has limits due to hardware constraints. Horizontal scaling requires a stateless design, where server state is managed externally (e.g., via databases or caches), ensuring seamless request handling across nodes.
Fault tolerance complements scalability by ensuring system availability despite failures. Circuit breakers are a key mechanism, acting as a safety valve to prevent cascading failures. When a server becomes unresponsive—due to a database outage, for instance—the circuit breaker trips, halting requests to that server and redirecting traffic to healthy nodes. After a cooldown period, it attempts to restore connectivity, minimizing downtime. Diagrams can depict this: a load balancer routing requests to a pool of servers, with a circuit breaker monitoring each node and failover servers standing by to take over.
Redundant servers enhance fault tolerance by providing backup capacity. In a geographically distributed setup, servers in different regions can serve as failover nodes, activated during local outages. For instance, a content delivery network might use redundant servers across continents, with DNS failover switching traffic to the nearest available node. Load balancers play a pivotal role, dynamically adjusting traffic based on server health, often monitored through heartbeat signals. In interviews, candidates can sketch a diagram showing a load balancer distributing requests to a primary server cluster, with a secondary cluster activated by a circuit breaker during failure, emphasizing proactive design for resilience.
Real-World Examples
Reference specific applications, such as how Google uses client-server architecture for search services, with clients querying distributed servers and CDNs delivering cached results. This shows practical application of theoretical concepts. Google’s search engine exemplifies client-server architecture on a global scale, where a user’s browser (client) sends a query to Google’s distributed server network. These servers, spread across data centers worldwide, process the request by accessing an index of web pages, leveraging sophisticated algorithms to rank results. The response is delivered rapidly, often within milliseconds, due to the architecture’s optimization. A key component is the use of Content Delivery Networks (CDNs), which cache static content (e.g., images, JavaScript files) closer to the user, reducing latency and server load. This layered approach—clients interacting with dynamic servers and static CDNs—demonstrates scalability and performance tuning in action.
Another example is Amazon’s e-commerce platform, which employs a multi-tier client-server model. Customers (clients) access the website or app, sending requests to application servers that handle product searches and transactions. These servers query a distributed database tier for inventory and pricing, while CDNs deliver product images and static pages. During high-traffic events like Prime Day, Amazon scales horizontally by adding servers, using load balancers to distribute requests and redundant data centers for fault tolerance. This real-world application highlights how the architecture supports massive concurrency and reliability.
In the financial sector, online banking systems utilize client-server architecture to secure transactions. A banking app (client) sends a request to authenticate a user, processed by an application server that verifies credentials against a secure database. Asynchronous calls may handle fund transfers, notifying the client via push notifications, while redundant servers ensure availability during peak usage. This example underscores the model’s role in ensuring security and consistency, critical in regulated industries.
These examples illustrate practical implementations of scalability, fault tolerance, and optimization. In interviews, candidates can expand on how Google’s use of CDNs reduces server strain or how Amazon’s multi-tier design supports global reach, connecting theoretical concepts to tangible outcomes. Discussing these cases with a focus on architectural decisions—such as choosing distributed servers over a monolithic setup—reinforces a deep understanding of client-server principles.
Conclusion
Client-server architecture remains a cornerstone of distributed systems, offering a robust framework for building scalable and efficient applications. By mastering its fundamentals, including the request-response pattern, variations, and strategic considerations, professionals can design systems that meet diverse requirements. This understanding is invaluable in system design interviews, where articulating architectural decisions and trade-offs is paramount. The model’s evolution continues to shape technological advancements, ensuring its relevance in an ever-changing digital landscape.



